
You’ve read the Kubernetes security docs. You know to set appArmorProfile: RuntimeDefault and seccompProfile: RuntimeDefault. You’ve ticked the CIS Benchmark boxes. And yet, if a container in your cluster were compromised right now, you might be surprised by what these controls would — and wouldn’t — stop.
This post is for engineers who’ve moved past configuration and want to reason about AppArmor and seccomp under pressure: their real enforcement models, where each fails, how they interact, how to manage them at scale, and what breaks first in production.
If you haven’t read the companion post on syscalls — Syscalls in Kubernetes: The Invisible Layer That Runs Everything — the enforcement mechanics below will make more sense with that foundation. Both controls operate on the syscall path; understanding what a syscall is and how it traverses the kernel is prerequisite context.
Table of Contents
- Why Platform Teams Should Care
- How the Kernel Enforces Security: Not a Pipeline
- From Syscall to Enforcement: The Full Execution Path
- The Runtime Default Trap
- Managing Profiles at Scale: Declarative or Nothing
- Writing a Real Profile: The Rule Model
- What AppArmor Won’t Stop
- AppArmor vs. Seccomp vs. SELinux: An Opinionated Take
- Seccomp: Deeper Than You Think
- A Threat Scenario: Container Escape Attempt
- What Breaks First in Production
- Performance Considerations
- A Production-Grade Pod Spec
- Observability: Catching Denials Before They Become Incidents
- Compliance Mapping
- A Realistic Failure Postmortem
- AppArmor’s Threat Model Boundary
- The Operational Cost of AppArmor
- Common Anti-Patterns
- Platform Team Playbook
- Designing for Control Failure
- Key Takeaways
- The Real Purpose of AppArmor
- If You Remember Only One Thing Per Control
- Closing Thoughts
Why Platform Teams Should Care
Most Kubernetes clusters already run with several security controls in place:
- Pod Security Standards at admission
- seccomp
RuntimeDefaultfiltering syscalls - NetworkPolicies governing traffic paths
- RBAC limiting API surface
So why add AppArmor to that stack?
Because those controls primarily restrict what a container can ask the kernel to do — not what resources it can access once it’s running. AppArmor fills a specific gap in that model:
| Control | What it restricts |
|---|---|
| Capabilities | Privileged kernel operations |
| Seccomp | Syscall invocation surface |
| NetworkPolicy | Network ingress/egress paths |
| AppArmor | Filesystem + kernel object access |
For platform teams operating multi-tenant clusters, this gap matters for two distinct reasons:
Containment. A compromised container running under a tight AppArmor profile cannot read /etc/shadow, traverse /proc/*/maps, write to /sys/kernel/**, or access service account tokens it wasn’t explicitly granted. The blast radius of a post-exploitation scenario is substantially smaller.
Detection signal. AppArmor denials fire early. When an attacker inside a container attempts reconnaissance — reading process maps, accessing credential paths, probing kernel interfaces — they hit AppArmor rules before they hit application-level controls. In many real incidents, AppArmor denial logs are the first signal that something is wrong, appearing minutes before behavioral anomalies surface in application logs.
Without mandatory access controls like AppArmor or SELinux, a compromised container often has far broader read access to the host filesystem and /proc namespace than platform teams realize — even under PSS Restricted. AppArmor is the layer that makes that access explicit and auditable.
How the Kernel Enforces Security: Not a Pipeline
A common mental model is that capabilities, AppArmor, and seccomp form an ordered enforcement stack. That’s a useful simplification, but it’s not how the kernel works — and the difference matters when you’re reasoning about bypasses.
All three are enforced inside the Linux kernel, but at different enforcement points with different objects:
- Capabilities gate privileged operations at the point they’re requested (e.g.,
CAP_NET_BIND_SERVICEbefore binding to a port below 1024). - Seccomp intercepts syscalls before they execute, using a BPF filter to allow, deny, or trap them.
- AppArmor is a Linux Security Module (LSM) that hooks into kernel object access — mediating access to files, sockets, capabilities, and IPC based on a per-process policy.
There is no strict serial pipeline. A process action may be evaluated against all three simultaneously, each at their respective hook point.
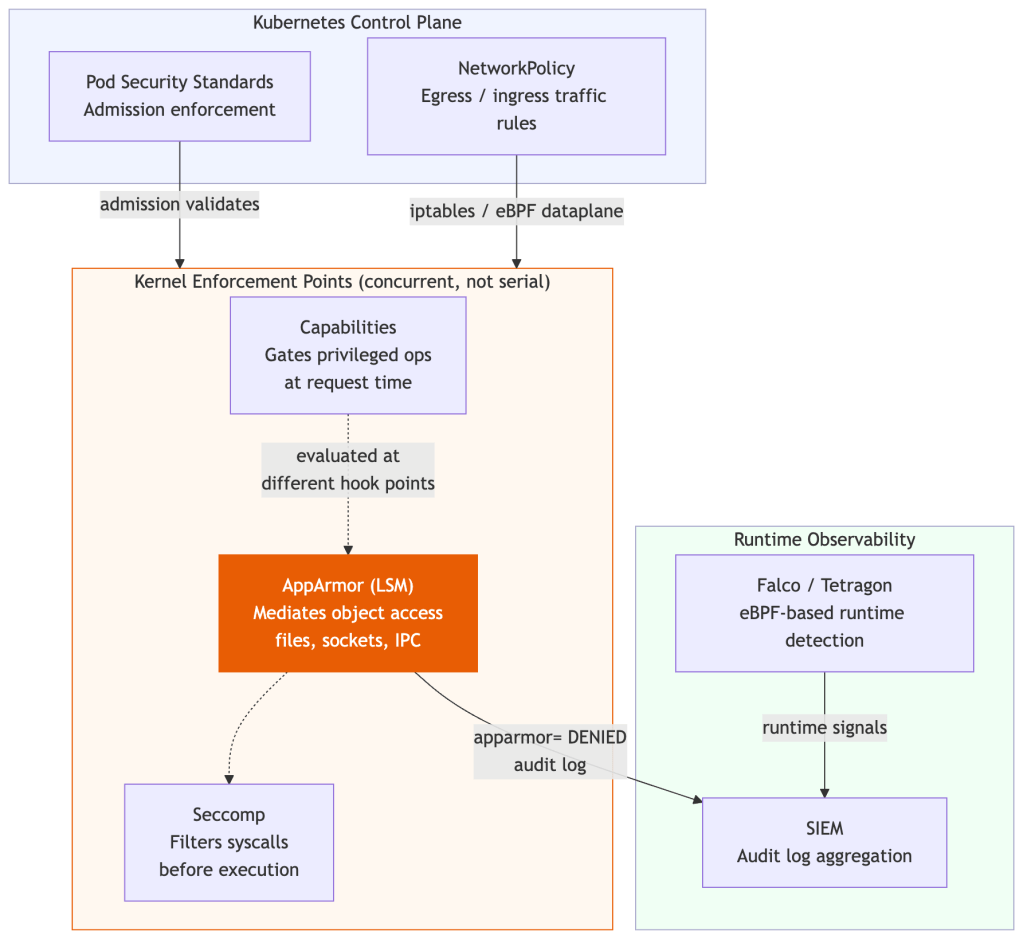
AppArmor is uniquely path-aware in a way that neither capabilities nor seccomp are — it can express “this process may read /etc/nginx/** but not /etc/passwd” — which is why it complements rather than duplicates the others.
From Syscall to Enforcement: The Full Execution Path
Before diving into each control individually, it’s worth being precise about when each fires. The ordering matters when you’re reasoning about bypasses — and it’s commonly misunderstood.
When a container process makes a syscall, here’s the actual sequence inside the kernel:
User Process │ └── syscall() ← ring 3 → ring 0 transition │ ├── seccomp filter (classic BPF) │ │ │ ├── KILL / ERRNO / TRAP / NOTIFY → exit here, never reaches kernel │ └── ALLOW → continue │ ├── kernel executes syscall logic │ │ │ └── LSM hooks fire (AppArmor / SELinux) │ │ │ ├── path / capability / network label check │ └── DENY → EACCES, operation aborted │ ├── capability checks (if privileged op requested) │ │ │ └── e.g. CAP_SYS_ADMIN for mount(), CAP_NET_RAW for raw sockets │ └── actual resource access (filesystem, network, IPC)
The critical implication: seccomp executes before LSM hooks. In most common syscall paths, seccomp is evaluated at syscall entry, followed by LSM hooks (AppArmor/SELinux) and capability checks during operation-specific validation — the exact interleaving varies by syscall and operation type, but the invariant that matters is: a syscall denied by seccomp never reaches the AppArmor evaluation point. Conversely, a syscall allowed by seccomp is still subject to AppArmor’s access controls on what that syscall can touch.
Capabilities complete the triad. They’re evaluated alongside LSM hooks for many operations and gate the privilege level of what a process can do — independent of both which syscalls it can invoke (seccomp) and which objects it can access (AppArmor). In practice, dropping capabilities is often the simplest way to eliminate entire exploit paths before seccomp or AppArmor need to engage. Dropping CAP_SYS_ADMIN removes more attack surface with one line than most seccomp tuning achieves:
- Seccomp → reduce what the kernel will execute
- AppArmor → reduce what processes can access
- Capabilities → reduce what processes are privileged to do
This is why the three controls are complementary by design, not redundant:
- Seccomp answers: can this syscall be invoked at all?
- AppArmor answers: given this syscall is allowed, what can it operate on?
- Capabilities answers: does this process hold the privilege required for this operation?
A workload with all three configured correctly gets seccomp narrowing the callable surface, capabilities bounding privilege, then AppArmor restricting what permitted syscalls can reach. Remove any layer and the others become your only backstop.
AppArmor reduces blast radius. Seccomp reduces reachable attack surface.
These are different threat properties. Seccomp blocking mount() means the exploit path requiring mount() simply cannot execute — the kernel never sees it. AppArmor can’t block a syscall entirely (it operates after kernel entry), but it can block every object that syscall would have reached. They defend different dimensions.
One insight that gets lost in feature comparisons: most container escapes don’t bypass all controls — they exploit the gaps between them. CVE-2022-0492 required unshare() and mount() in sequence; seccomp’s RuntimeDefault blocked mount(), AppArmor’s default profile independently denied it too. Either layer alone would have stopped the exploit. Security failures are rarely about a single mechanism failing — they’re about assumptions breaking at the boundaries between seccomp, LSMs, and capabilities. Understanding those boundaries is what this article is actually about.
The Runtime Default Trap
RuntimeDefault is not a single profile. It’s an instruction to the container runtime to apply its own default profile — and that profile differs across runtimes.
- containerd delegates to the
default.profileshipped by the runtime shim. - CRI-O uses a profile derived from the OCI runtime spec with its own modifications.
- Docker uses its own
docker-defaultprofile (relevant in non-Kubernetes contexts).
Modern runtimes have largely converged on a similar baseline, but differences still exist in rule ordering, abstraction includes, and which operations are allowed. In hardened environments, those deltas matter — you’re reasoning about a security envelope you don’t fully control.
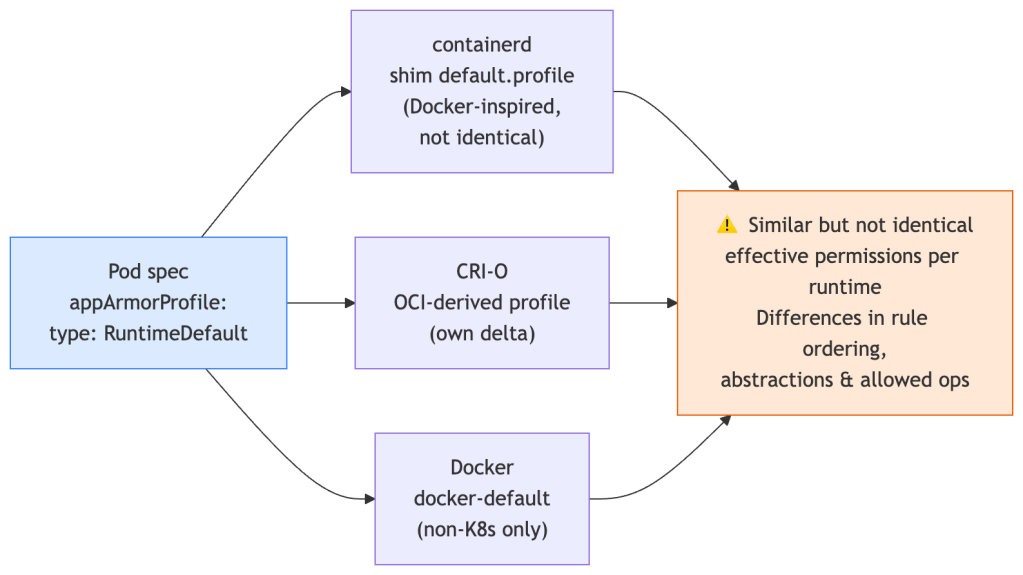
The only way to get a consistent, auditable security envelope is to manage your own Localhost profiles:
securityContext: appArmorProfile: type: Localhost localhostProfile: my-org/nginx-v2
That localhostProfile value is a path relative to /etc/apparmor.d/ on the node. Which brings us to the hard problem: getting profiles onto nodes reliably.
The platform implication for multi-cluster environments: two clusters running identical pod manifests can have subtly different effective security envelopes depending on their runtime. This creates configuration drift that is largely invisible in CI pipelines — a security review comparing manifests will see the same RuntimeDefault annotation, but the actual enforcement may differ. The only reliable mitigation is to treat profiles as versioned infrastructure and manage them declaratively, as covered in the next section.
Managing Profiles at Scale: Declarative or Nothing
The naive approach is a DaemonSet that writes profile files and runs apparmor_parser -r. This works until it doesn’t — profile updates require careful ordering, new nodes joining the cluster won’t have profiles until the DaemonSet pod schedules there, and you have no audit trail.
At cluster scale, profile lifecycle must be reconciled declaratively. The Security Profiles Operator (SPO) is currently the most production-ready implementation of that model — a Kubernetes-native controller that manages AppArmor (and seccomp) profiles as first-class CRDs.
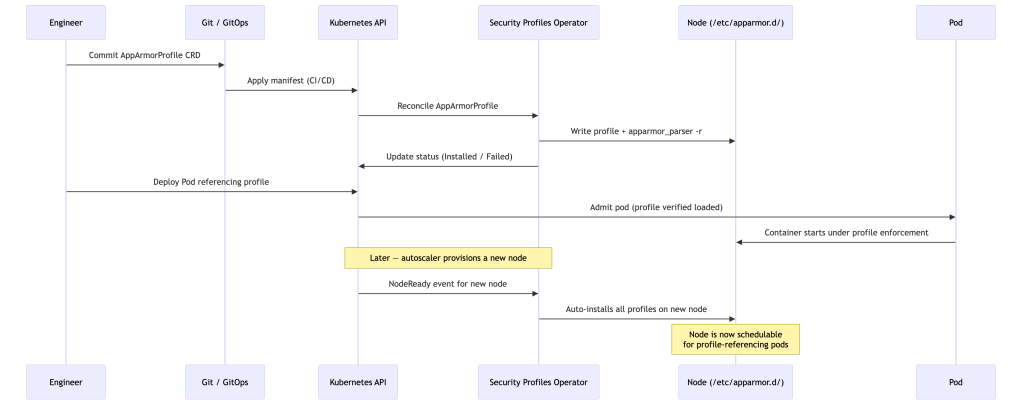
SPO reconciles profiles onto nodes, surfaces violations as Kubernetes events, and integrates with OPA/Gatekeeper to enforce that pods only reference profiles that are actually loaded. It also has a --record mode that observes a running workload and generates a profile from its real behavior — invaluable for brownfield workloads.
Here’s what a real SPO-managed AppArmorProfile CRD looks like for an nginx container. The Kubernetes metadata section is standard — name and namespace are how pods reference the profile. The spec.policy field is a raw AppArmor policy written in AppArmor’s own language, which SPO writes directly to /etc/apparmor.d/ on each node:
apiVersion: security-profiles-operator.x-k8s.io/v1alpha1kind: AppArmorProfilemetadata: name: nginx-restricted # pods reference this name in appArmorProfile.localhostProfile namespace: production # profile is scoped to this namespacespec: policy: | #include <tunables/global> # defines @{PROC}, @{HOME} and other path variables profile nginx-restricted flags=(attach_disconnected) { # attach_disconnected: allow profile to apply even if the binary path # isn't reachable at load time (common in containers with overlayfs) #include <abstractions/base> # allows libc, locale files, /dev/null etc. #include <abstractions/nameservice> # allows DNS resolution (/etc/resolv.conf, nsswitch) # Allow outbound TCP only — no UDP, no raw sockets network inet tcp, network inet6 tcp, # Binary: map+read+execute (mr). Denies writes to the nginx binary itself. /usr/sbin/nginx mr, /etc/nginx/** r, # read-only access to all nginx config files /var/log/nginx/** w, # write access for access/error logs /var/cache/nginx/** rw, # read+write for proxy cache and temp files /tmp/** rw, # read+write for nginx temp upload/body buffers # Explicit denials — these take precedence over any allow rules above deny /proc/sys/kernel/core_pattern w, # prevent overwriting core dump handler (container escape vector) deny @{PROC}/*/mem rw, # prevent reading/writing any process's memory deny /sys/** w, # prevent writing to sysfs (kernel tunable manipulation) }
Writing a Real Profile: The Rule Model
AppArmor rules follow a simple pattern: [qualifier] [resource] [permissions]. But the devil is in the details — particularly the path model.
# File rules/etc/nginx/** r # read all files under /etc/nginx/var/log/nginx/*.log w # write to log files/tmp/nginx-*/ rw # read/write temp directories/run/nginx.pid rw # read/write PID file# Capability rulescapability net_bind_service, # allow binding to ports < 1024capability dac_override, # override file permission checks (avoid if possible)# Network rulesnetwork inet tcp,network inet6 tcp,deny network raw, # deny raw sockets explicitly# Deny dangerous kernel paths explicitlydeny /proc/sys/kernel/** w,deny @{PROC}/*/maps r, # prevent reading process memory maps (explicit deny required)
A profile worth deploying has explicit deny rules, not just allowances. The deny keyword takes precedence over allow rules and is your backstop against profile inheritance tricks. Default-deny with explicit allows is the correct mental model.
The Path-Based Trap
AppArmor evaluates rules against resolved path strings, not inodes. This is a non-obvious but important limitation.
If an attacker inside a container can manipulate how paths resolve — through bind mounts, symlinks, or mount namespace tricks — they may be able to access a file via an allowed path that reaches an inode your policy intended to restrict. For example:
# If /allowed-dir is permitted and an attacker can bind-mount /etc/shadow there:mount --bind /etc/shadow /allowed-dir/shadow # now readable via allowed path
Well-written profiles must pair with readOnlyRootFilesystem: true and careful namespace configuration to close this class of bypass. It’s not a reason to avoid AppArmor, but it’s a reason to understand what you’re actually enforcing.
Generating a starting profile: Use aa-genprof to record behavior in complain mode, then tighten from there. For containers, SPO’s --record mode is cleaner.
# Load a profile in complain mode (logs denials, doesn't enforce)apparmor_parser -C /etc/apparmor.d/my-profile# Watch would-be denials in real timejournalctl -k -f | grep apparmor
What AppArmor Won’t Stop
This is the section most blog posts skip.
AppArmor Coverage vs. Threat Severity HIGH │ ✗ Kernel CVE bypass ║ ✓ Cgroup release_agent escape │ ✗ In-memory / ROP chain ║ ✓ Write to /sys or /proc/kernel S │ ✗ Network exfiltration ║ ✓ Service account token read E │ ✗ Misloaded profile (silent) ║ ✓ Read /proc/*/maps (recon) V │ ✗ Path traversal/bind mount ║ E ─────┼──────────────────────────────╫────────────────────────────────R │ ║ I │ (no threats here — ║ ✓ Raw socket creation T │ low severity threats ║ Y │ not covered by AA ║ │ are acceptable risk) ║ LOW │ ║ └──────────────────────────────╨──────────────────────────────── LOW COVERAGE HIGH COVERAGE ◄── AppArmor Coverage ──► ✗ = AppArmor does NOT cover this threat (needs other controls) ✓ = AppArmor blocks this (if profile is correctly written)
Network exfiltration: AppArmor can allow or deny protocol families (TCP, UDP, raw) but has no concept of destination IPs or domains. A process with network inet tcp allowed can exfiltrate data to any external endpoint. That’s NetworkPolicy’s domain — and the two must work together.
In-memory attacks: AppArmor is path-based and capability-based. It has no visibility into what happens in memory. A process with permitted capabilities can still execute heap sprays, ROP chains, or in-process exploitation. Runtime detection tools like Falco or Tetragon — which observe syscall patterns using eBPF — are the right layer for this.
Kernel vulnerabilities: AppArmor is a kernel module that hooks via LSM interfaces. An exploit that compromises the kernel below those hooks bypasses AppArmor entirely. CVE-2022-0185 (a kernel heap overflow enabling container escape) is a real example — no AppArmor profile would have stopped it because the exploit occurred before LSM enforcement points were reached.
Misloaded profiles: Depending on your runtime version and Kubernetes version, a missing Localhost profile may either cause pod admission failure or allow the container to start without confinement. This variance is precisely why profile lifecycle management must be automated — the SPO’s status reporting makes this observable; bare annotation approaches fail silently.
Path-based bypasses: As described above — bind mounts and mount namespace manipulation can cause policy to evaluate against a path that resolves to an unintended inode.
AppArmor vs. Seccomp vs. SELinux: An Opinionated Take
These three are frequently described as interchangeable. They’re not — they enforce different things at different kernel hook points.
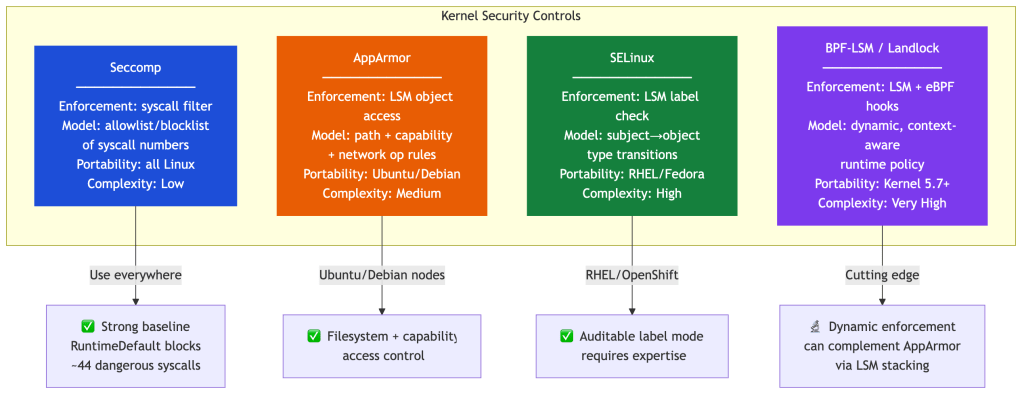
Choosing AppArmor vs. SELinux at Platform Level
Most platform teams don’t choose between AppArmor and SELinux for purely technical reasons. They choose based on node OS standardization — which is already determined before the security conversation happens.
| Node OS | MAC default | Practical choice |
|---|---|---|
| Ubuntu / Debian | AppArmor | Use AppArmor |
| RHEL / CentOS / OpenShift | SELinux | Use SELinux |
| Heterogeneous (both) | Neither by default | Pick one, standardize |
The operational cost of running both MAC engines across heterogeneous nodes — maintaining separate toolchains, policy languages, expertise, and audit pipelines — almost always outweighs any technical benefit. In practice, consistency of tooling and policy management matters more than the underlying MAC engine.
Control Failure Mode Comparison
This is the table most comparison posts omit: not what each control does, but what each control fails to stop.
| Scenario | Seccomp | AppArmor | Why |
|---|---|---|---|
Block mount() entirely | ✅ | ❌ | Seccomp can block the syscall number; AppArmor mediates objects, not syscall invocation |
Restrict /etc/passwd reads | ❌ | ✅ | Seccomp can’t dereference path arguments; AppArmor is path-aware |
| Stop kernel exploit (pre-LSM) | ❌ | ❌ | Both operate inside the kernel; pre-hook exploits bypass both |
Stop open() misuse on allowed fd | ❌ | ✅ | Seccomp allows open() broadly; AppArmor restricts what it can open |
Block namespace-creating clone() | ✅ | ❌ | Argument filtering on clone flags; AppArmor doesn’t intercept syscall invocation |
| Prevent network exfiltration | ❌ | ⚠️ Partial | Seccomp can’t; AppArmor can block protocol families but not destinations |
| Detect in-memory exploits | ❌ | ❌ | Neither has memory visibility; needs Falco/Tetragon |
The table makes one thing clear: these two controls have almost no overlap in what they stop. They’re not alternatives — they’re complements covering different axes of the attack surface.
When Is seccomp Alone Enough?
Seccomp RuntimeDefault blocks syscalls that are rarely needed and frequently abused — keyctl, kexec_load, ptrace, mount, unshare, and others. For many workloads, this provides the most impactful risk reduction per unit of operational effort.
Add AppArmor when:
- You need path-level access control (restrict reads to specific filesystem subtrees)
- You’re running multi-tenant workloads and need isolation between namespace tenants
- You need explicit capability access control beyond what the Pod
securityContextexpresses - You’re building toward a compliance posture that requires MAC
Stay with seccomp-only when:
- Your nodes are heterogeneous (mixed OS) and profile management would span both engines
- Your workloads are internal tooling with low breach impact
- The operational cost of profile lifecycle management exceeds your team’s capacity
The right answer is not “AppArmor everywhere” — it’s “AppArmor where the containment value exceeds the operational cost.”
LSM Stacking: The Frontier
Modern Linux kernels (5.7+) support LSM stacking, which means AppArmor, SELinux, BPF-LSM, and Landlock can coexist in the same kernel, each enforcing at their respective hooks — though the exact combinations available depend on kernel configuration and distribution defaults. In hardened environments where stacking is supported, this enables layered MAC enforcement that goes well beyond any single module.
Tetragon takes this further: where AppArmor is a static policy engine evaluated at access time, Tetragon uses eBPF to enforce dynamic policy based on runtime context — process ancestry, argument values, network connection state — things AppArmor cannot express. If you’re running Tetragon, AppArmor and eBPF enforcement are complementary, not competing.
The practical answer for most clusters: seccomp everywhere as a syscall filter, AppArmor on Ubuntu/Debian nodes for filesystem and capability restrictions, and SELinux on RHEL-based nodes. On kernel 5.7+, investigate BPF-LSM for workloads that need dynamic policy.
Seccomp: Deeper Than You Think
The comparison section above treats seccomp as a peer of AppArmor. It is — but most engineers use it at a much shallower level than AppArmor because the documentation stops at “configure RuntimeDefault and move on.” Here’s what staff-level seccomp understanding looks like.
The cBPF Filter Model
Seccomp filters are classic BPF (cBPF) programs, not eBPF. This distinction matters:
- Filters are compiled into a set of instructions evaluated in kernel context on every syscall entry
- Execution is intentionally constrained: no loops, bounded instruction count, no memory allocation
- This constraint is a feature — it guarantees the filter cannot hang or crash the kernel
Unlike eBPF observability tools (Falco, Tetragon) which can maintain maps, call helper functions, and do complex processing, a seccomp filter is a simple decision function: given this syscall number and these argument values, return an action. That simplicity is why seccomp is evaluated first — before any LSM hook, before capability checks, before kernel logic runs at all.
The filter is attached per-process (inheritable by children) and evaluated on every syscall entry. Attaching a filter requires CAP_SYS_ADMIN or the no_new_privs bit to be set — which is why allowPrivilegeEscalation: false is a prerequisite to meaningful seccomp enforcement.
Return Actions (More Than Allow/Deny)
RuntimeDefault uses SCMP_ACT_ERRNO for blocked syscalls. But seccomp has a richer action set that custom profiles can leverage:
| Action | Behavior | Use Case |
|---|---|---|
SCMP_ACT_ALLOW | Syscall proceeds | Normal operation |
SCMP_ACT_ERRNO | Returns configurable errno | Default for RuntimeDefault; graceful failure |
SCMP_ACT_KILL_PROCESS | Immediately kills the process | Highest-risk syscalls (ptrace, kexec_load) |
SCMP_ACT_LOG | Logs the syscall, allows it | Audit mode — building a profile from production traffic |
SCMP_ACT_TRACE | Notifies a ptrace tracer | Policy development tooling |
SCMP_ACT_NOTIFY | Sends event to userspace supervisor via fd | See below |
The most powerful and least-known action is SCMP_ACT_NOTIFY (introduced in kernel 5.0). It sends the syscall event to a userspace supervisor via a file descriptor — the container’s syscall is paused until the supervisor makes a decision. This turns seccomp into a programmable enforcement point: a policy engine can inspect the syscall’s arguments, look up process context, consult external state, and then approve or deny — all before the kernel executes anything. This is how tools like sysbox implement OCI-compliant syscall interception without full gVisor overhead.
For most Kubernetes workloads you’ll never need SCMP_ACT_NOTIFY, but understanding it exists clarifies what seccomp is: not just a static blocklist, but a kernel-userspace interception interface with real programmability.
Argument Filtering: The Underused Power Feature
Most engineers know seccomp filters on syscall numbers. Fewer know it can filter on syscall arguments.
Seccomp’s cBPF instructions can inspect the syscall argument registers. This enables policies like:
{ "syscalls": [ { "names": ["clone"], "action": "SCMP_ACT_ALLOW", "args": [ { "index": 0, "value": 2114060288, "op": "SCMP_CMP_MASKED_EQ" } ] } ]}
Concretely, argument filtering enables:
- Allow
open()for read-only, deny write: check the flags argument forO_RDWRorO_WRONLY - Block
clone()with namespace-creating flags: the RuntimeDefault profile already does this — it doesn’t blockcloneentirely (threads need it), it blocks theCLONE_NEWUSER/CLONE_NEWNSflag combinations that enable container escapes - Restrict
prctl()operations: allowPR_SET_NAME(used by many runtimes), blockPR_SET_DUMPABLEandPR_CAP_AMBIENT
Argument filtering is how RuntimeDefault blocks namespace-creating clone() without breaking thread creation in multithreaded applications — a subtlety that gets lost in “seccomp blocks 44 syscalls” summaries.
Two Non-Obvious Properties
Seccomp filters are per-thread, not per-container. The filter is attached to a process and inherited by threads and child processes. In multithreaded applications, each thread runs under the same filter — but thread-specific behavior (signal handling, JVM internal threads, async runtimes) can produce syscall patterns that weren’t covered during profile generation. JVM profiling windows that only observed the main application thread frequently miss the GC thread’s madvise and mmap patterns.
Seccomp is not namespace-aware. The filter applies equally regardless of which container, namespace, or cgroup the thread belongs to. A seccomp filter attached to a process doesn’t know it’s running inside a container. This is both a strength (it can’t be bypassed by namespace tricks) and a limitation (you can’t express “allow mount() inside the container’s mount namespace but deny it in the host namespace” — that distinction lives in the capability and LSM layers, not seccomp).
What Seccomp Won’t Stop
Seccomp has no concept of paths. It sees openat(AT_FDCWD, "/etc/shadow", O_RDONLY) as a permitted openat syscall — unless you’ve also checked the path argument. But path arguments are memory pointers, not inline values, and cBPF can’t dereference pointers. Seccomp fundamentally cannot enforce path-level access control. That’s AppArmor’s domain.
Seccomp cannot enforce stateful policies. Each syscall decision is independent. Seccomp cannot say “allow the first open() to this fd but deny the third” or “allow connect() unless the previous execve() was suspicious.” For stateful, context-aware enforcement, you need eBPF-based tools (Tetragon) or SCMP_ACT_NOTIFY with a userspace supervisor.
Seccomp cannot prevent allowed syscall abuse. If write() is allowed and an attacker has an open fd to a sensitive file, seccomp won’t stop the write. Allowing a syscall means allowing it — what it operates on is AppArmor’s responsibility.
Argument filtering has coverage limits. Pointer arguments (file paths, struct pointers) cannot be dereferenced by cBPF. Only integer-valued arguments (flags, fd numbers, mode values) can be reliably checked.
Seccomp answers “can this syscall be invoked?” but not “what does this syscall operate on?“
A Threat Scenario: Container Escape Attempt
Let’s make this concrete. An attacker has achieved code execution inside a container via a deserialization vulnerability. What happens?
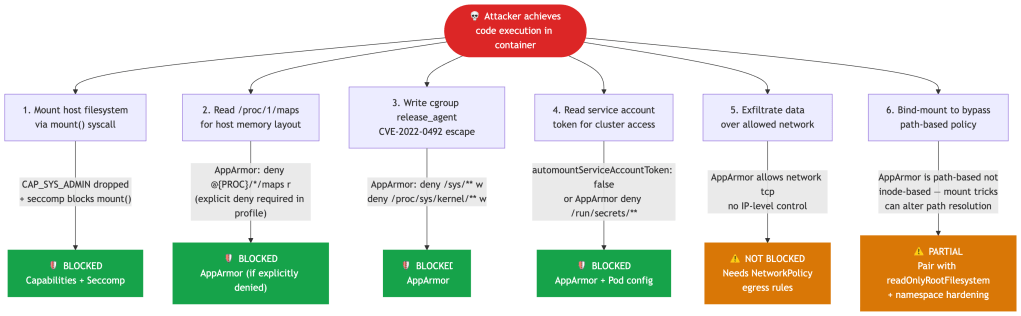
Note that attack vector 2 is only blocked if you’ve explicitly added deny @{PROC}/*/maps r to your profile. Many RuntimeDefault profiles do not include this denial. This is a good example of why “we have AppArmor” and “we have AppArmor enforcing what we think it is” are different claims.
What Breaks First in Production
Theory is necessary. Operational experience is different. Here’s what actually causes profile-related incidents:
Java and JVM workloads write to unexpected temp paths at startup — often derived from system properties and JDK version. A profile tight enough to deny /tmp/hsperfdata_* will break JVM health checks. Generate profiles from running workloads, not from documentation.
Dynamic language runtimes (Python, Ruby, Node.js) load shared libraries and modules from paths that vary by distribution and package version. /usr/lib/x86_64-linux-gnu/** may need to be explicitly allowed, and that path is distribution-specific.
Sidecars accessing shared volumes: If your app container and a sidecar (e.g., an Envoy proxy or log shipper) share an emptyDir, both containers need profiles that permit access to that volume’s underlying path. The actual path under /var/lib/kubelet/pods/ is unpredictable — use @{run} and path globs carefully, or use a dedicated volume mount path that’s consistent.
Health and readiness probes: Kubernetes exec probes run inside the container’s process namespace. If your probe invokes /bin/sh or /bin/curl and your profile restricts shell execution, probes will fail. Either allow the probe binary explicitly or switch to HTTP/TCP probes that don’t require exec.
Profile load ordering on node startup: If a node reboots and the SPO pod hasn’t yet reconciled profiles before a workload pod schedules, the workload pod may fail admission. Build node readiness checks that verify profile presence, or use pod disruption budgets and node cordoning during maintenance windows.
Performance Considerations
AppArmor’s overhead is generally low, but not zero, and it scales with profile complexity.
The cost is incurred at file open, exec, and network operations — each requires an LSM hook traversal and a policy lookup. For most workloads, this is imperceptible. For workloads doing high-frequency file I/O (logging pipelines, database engines, build systems), a dense profile with many path rules can add measurable latency to path lookups.
Practical guidance: keep profiles focused. A profile with 20 precise rules is faster and easier to audit than one with 200 broad globs. Avoid /** catch-alls on performance-sensitive paths — use specific subtree rules. And in complain mode, audit noise from high-frequency deny events can itself affect throughput; don’t leave workloads in complain mode indefinitely.
A Production-Grade Pod Spec
apiVersion: v1kind: Podmetadata: name: hardened-app namespace: productionspec: automountServiceAccountToken: false # disable default SA token mount — most pods don't need API access securityContext: # pod-level: applies to all containers runAsNonRoot: true # kubelet rejects the pod if the image runs as UID 0 runAsUser: 1001 # explicit UID — avoid root (0) and well-known service UIDs runAsGroup: 1001 # primary GID for the process fsGroup: 1001 # volume files are chowned to this GID on mount seccompProfile: type: RuntimeDefault # use the container runtime's built-in seccomp profile (~44 blocked syscalls) # move to Localhost + custom profile for high-security workloads containers: - name: app image: my-org/app:1.4.2 # pin to digest in production; tags are mutable securityContext: # container-level: overrides pod-level where both exist appArmorProfile: type: Localhost # use a node-loaded custom profile, not RuntimeDefault localhostProfile: my-org/app-v1 # path relative to /etc/apparmor.d/ — must be loaded by SPO before pod starts allowPrivilegeEscalation: false # prevents setuid binaries and sudo from granting more privilege than the parent readOnlyRootFilesystem: true # container filesystem is immutable — writes go only to explicit volume mounts capabilities: drop: - ALL # drop every capability Linux grants by default add: - NET_BIND_SERVICE # re-add only if binding to ports < 1024; remove if app uses port >= 1024 volumeMounts: - name: tmp mountPath: /tmp # writable scratch space — required by many runtimes even under readOnlyRootFilesystem - name: cache mountPath: /var/cache/app # app-specific writable path; scope this as narrowly as possible volumes: - name: tmp emptyDir: {} # ephemeral, node-local; wiped on pod restart — not for persistent data - name: cache emptyDir: {} # same — both volumes exist only to satisfy readOnlyRootFilesystem
A few non-obvious choices: automountServiceAccountToken: false removes the default credential most pods get but rarely need. The emptyDir volumes provide writable space within a readOnlyRootFilesystem: true constraint — without them, many runtimes crash on startup trying to write to /tmp. Drop ALL capabilities and add back only what’s needed; NET_BIND_SERVICE is the only one most web services require.
Note also what Restricted PSS enforces at admission: it validates that appArmorProfile is present and set to RuntimeDefault or Localhost, but it does not validate the strength or content of the referenced profile. Admission compliance and actual security posture are not the same thing.
Observability: Catching Denials Before They Become Incidents
AppArmor logs to the kernel audit subsystem:
# Live denial streamjournalctl -k -f | grep 'apparmor="DENIED"'# Example denial entrykernel: audit: type=1400 audit(1708012345.123:42): apparmor="DENIED" operation="open" profile="my-org/app-v1" name="/proc/1/maps" pid=12345 comm="sh" requested_mask="r" denied_mask="r" fsuid=1001 ouid=0
Distinguishing seccomp denials from AppArmor denials is a practical skill that gets skipped in documentation. They surface differently:
| Seccomp denial | AppArmor denial | |
|---|---|---|
| Syscall result | EPERM or ENOSYS (configurable) | EACCES (access denied) |
| Kernel log | None by default (use SCMP_ACT_LOG to enable) | Visible in dmesg and audit log immediately |
| Log format | No apparmor= field; show up only if SCMP_ACT_LOG action used | apparmor="DENIED" with operation, profile, name, comm fields |
| How to distinguish | Application sees EPERM but nothing in journalctl -k | grep apparmor | Explicit audit log entry with profile name |
When a container fails with Operation not permitted and you see nothing in the AppArmor audit log, seccomp is the likely culprit. Add SCMP_ACT_LOG to your profile’s unknown syscalls during profiling to surface them — the Security Profiles Operator’s --record mode does this automatically.
The operation, profile, name, and comm fields tell you exactly what was denied, by which profile, from which binary. When a denial fires, the triage path matters:
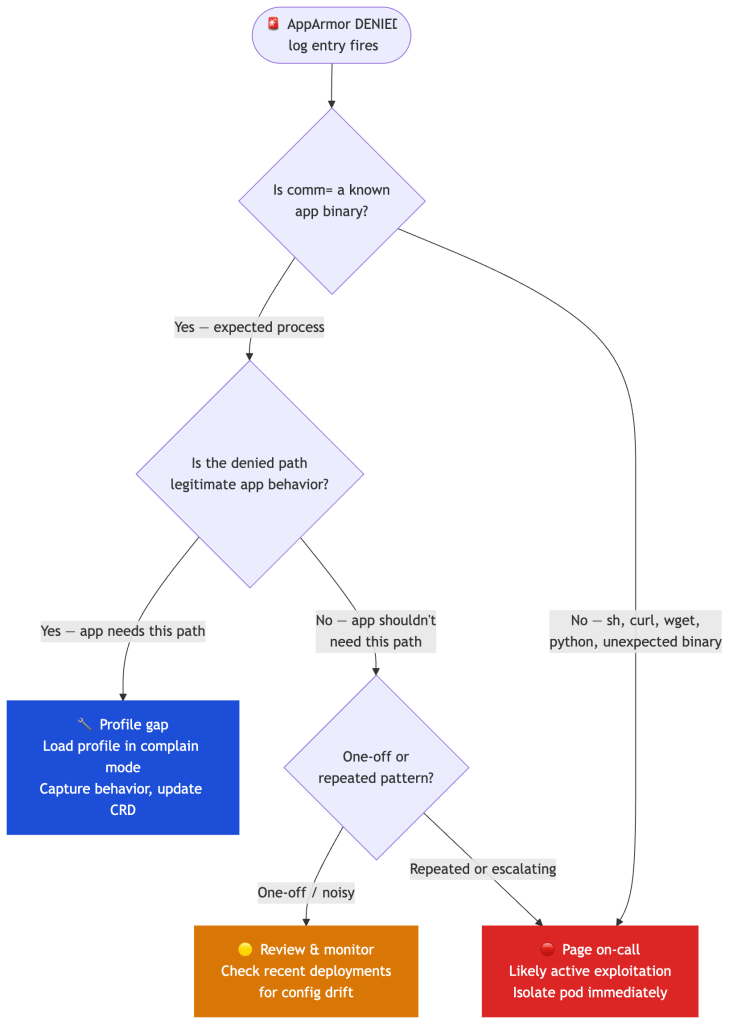
A denial from a known binary hitting a path the app shouldn’t need is a high-fidelity signal — treat it as an incident until proven otherwise. Feed these logs into your SIEM(Security Information and Event Management) with a volume-based alert on any single pod.
Compliance Mapping
| Control | Standard | Requirement |
|---|---|---|
| Mandatory Access Control | CIS Kubernetes Benchmark 5.7.4 | Apply security context to pods/containers |
| Least privilege file access | NIST SP 800-190 §4.3.1 | Limit container runtime privileges |
| Restrict kernel capabilities | PCI DSS v4 Req 6.4 | Protect systems from known vulnerabilities |
| Restrict syscall surface | SOC 2 CC6.1 | Logical access controls |
| Pod Security Standards (Restricted) | Kubernetes native | appArmorProfile must be RuntimeDefault or Localhost |
Note the gap: compliance frameworks check for the presence of controls, not their effectiveness. PSS Restricted enforces that a profile is declared, not that it actually restricts anything meaningful. That’s your team’s responsibility to close.
A Realistic Failure Postmortem
Understanding where AppArmor goes wrong in practice is as important as knowing how to configure it. Here’s a failure mode that plays out more often than it should.
A platform team deploys a new microservice to production. They’ve done the right things: a custom Localhost profile, authored from SPO’s recorded output in staging, reviewed and tightened before go-live. The deployment succeeds. Pods are running. And then, three hours later, Kubernetes starts restarting pods due to failing readiness probes.
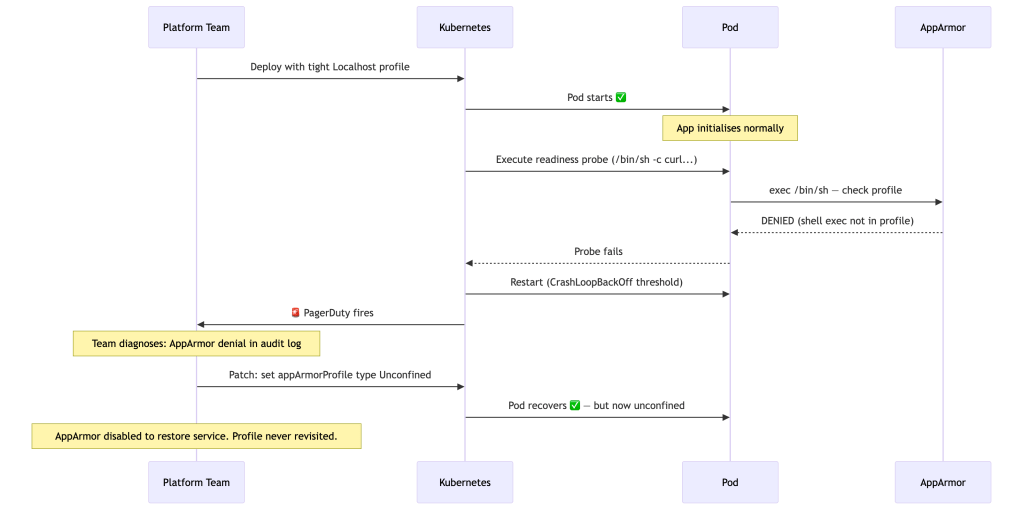
What went wrong: The profile was generated from the application process’s behavior, but exec probes spawn a separate shell inside the container that the profiling run never observed. The profile correctly represented the app — but not all the processes Kubernetes would run inside it.
The compounding failure: Under pressure at 2am, the team set type: Unconfined and moved on. That pod has been running without AppArmor enforcement for six months. Nobody notices because it’s not visible in normal kubectl output.
The systemic lesson: The root issue was not the profile itself — it was the rollout process. Security controls fail most often during deployment, not during steady state operation. The failure mode is predictable: profiles generated from synthetic or incomplete observation windows miss edge cases, and the incident response path of least resistance is to disable the control entirely.
Treat AppArmor enforcement like any other breaking infrastructure change: progressive rollout, canary namespaces, and automated rollback to complain mode — not to Unconfined.
The right rollout strategy:
- Deploy to a canary namespace with the profile in complain mode first (
flags=(complain)), even if you generated it from production traffic. - Monitor denials for 24–48 hours across all probe types, init containers, and sidecar interactions.
- Promote to enforce mode only after the denial stream is clean.
- If enforcement causes an incident, roll back to complain mode — never to
Unconfined. Complain mode preserves the security signal while restoring service. - Treat a post-incident
Unconfinedpod as technical debt with a ticket, not a resolved incident.
The lesson isn’t that AppArmor is fragile. It’s that profile coverage must be validated against everything the kernel will run in a container, not just the application binary.
AppArmor’s Threat Model Boundary
AppArmor is a meaningful control within a specific set of assumptions. Outside those assumptions, it provides weaker or no protection. Being explicit about this boundary is what separates operational security from security theater.
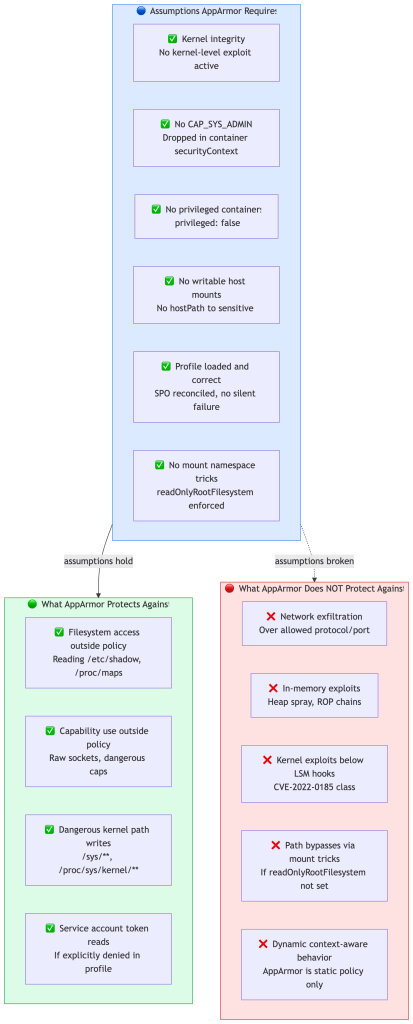
The most common way these assumptions break silently in real clusters:
- A team runs a debug container with
privileged: trueto diagnose an incident and never removes it. - A legacy workload requires
hostPathmounts that weren’t caught in policy review. - A node autoscaler provisions a new node type whose image doesn’t have the SPO-managed profiles loaded.
- An operator chart sets
appArmorProfile: type: Unconfinedfor convenience during development and the override is never removed before promotion.
None of these are AppArmor failures. They’re assumption violations. The control is only as strong as the assumptions underneath it — which is why security posture reviews should explicitly verify these preconditions, not just check that the field is set.
The Operational Cost of AppArmor
The real cost of AppArmor is not performance overhead — it’s policy maintenance.
Every Localhost profile you deploy becomes part of your platform’s API surface. Applications depend on it. Admission controllers enforce its presence. And unlike most Kubernetes configuration, profile changes can silently break applications in ways that only surface under specific runtime conditions.
The ongoing maintenance surface that teams underestimate:
- Profile lifecycle management — profiles must be versioned, reviewed, and retired as applications evolve. A profile that was accurate at authoring time may be wrong after a dependency upgrade or JDK version change.
- Runtime compatibility — when containerd or CRI-O ships a new version, default behavior can shift. Profiles that relied on implicit runtime behavior may need updates.
- Sidecar and probe coverage — every new sidecar (Envoy, log shipper, OTel collector) added to a namespace needs its own profile or must be explicitly covered. Forgetting this is how
Unconfinedexceptions accumulate. - Exception management under pressure — during incidents, the fastest resolution is always to disable the control. Without a clear policy on what constitutes a legitimate exception (and a process for revisiting it), profiles erode over time.
Without automation — SPO for lifecycle, GitOps for change tracking, SIEM alerts for denial spikes — AppArmor deployments tend to degrade into one of two failure modes: overly permissive profiles that allow nearly everything, or growing lists of Unconfined exceptions added during incidents and never revisited.
The question for platform teams is not “should we use AppArmor?” but “do we have the operational infrastructure to maintain it at the security level it needs to operate?”
Common Anti-Patterns
These are the patterns that undermine AppArmor in production, across organizations that have done the work to deploy it.
Treating RuntimeDefault as “secure enough.” It’s a reasonable baseline, but it’s not a security posture. RuntimeDefault does not restrict filesystem access, doesn’t prevent reading /proc/*/maps, and varies across runtimes. It’s a starting point, not a destination.
Generating profiles from synthetic or short-observation traffic. A profile generated from 30 minutes of staging traffic will miss weekly batch jobs, on-call runbook paths, slow-startup JVM behavior, and any probe interactions that didn’t fire during the window. Observation windows must cover full operational cycles — including failure modes.
Running security controls only in production. Profiles validated only in production are profiles you can’t roll back safely. Complain mode in staging, enforce in production, with CI comparison of denial delta between environments.
Setting Unconfined during incidents and not reverting. This is the most common way security posture degrades silently. Every Unconfined exception added under pressure is a permanent policy rollback unless tracked and scheduled for follow-up.
Not auditing profile drift. Applications change. Profiles don’t automatically change with them. An 18-month-old profile for a service that has been through three dependency upgrades is almost certainly wrong — either too permissive (allowing paths the app no longer needs) or insufficiently permissive (missing paths added in newer dependencies).
Alerting on absolute denial counts rather than deviation. Some workloads produce steady, low-level denial noise from probe edge cases or library behavior. Alerting on any denial will exhaust on-call teams; alerting on zero denials misses real events. Baseline first, then alert on deviation.
Platform Team Playbook
If you operate Ubuntu-based Kubernetes nodes and are building or hardening your security posture, here’s a concrete sequence. This isn’t theory — it’s the operational order that reduces the risk of each step breaking what the previous step protected.

A few implementation notes on the less obvious steps:
Step 1 before AppArmor: Seccomp RuntimeDefault is lower risk, higher portability, and easier to validate. Getting it in first means AppArmor is hardening a surface that’s already narrowed. Don’t try to do both simultaneously — sequence reduces blast radius.
Step 4 duration matters: 48 hours is a minimum. If your workload has weekly batch jobs, cron patterns, or on-call runbooks that trigger unusual paths, you need observation windows that cover those cycles. A profile generated from one hour of traffic will miss them.
Step 7 baselining: Before you alert on denial spikes, you need to know what “normal” looks like. Some workloads legitimately produce periodic denials from probe edge cases or library behavior that’s been allowed to be noisy. Baseline first, alert on deviation — not absolute counts.
Step 8 is the one teams skip: Profiles drift out of sync with applications as code changes. An overly permissive profile that hasn’t been reviewed in 18 months is security debt. Treat profile review as part of your service’s security hygiene, not a one-time setup task.
Designing for Control Failure
In real systems, controls fail. Profiles drift. Runtimes change defaults. Exceptions get introduced under pressure and never revisited. The value of layering is not redundancy — it’s graceful degradation.
When reasoning about your security posture, think through each layer’s failure mode:
If seccomp fails (missing profile, wrong defaults) → AppArmor still restricts filesystem and object access → Capabilities still bound privilege → NetworkPolicy still governs egressIf AppArmor fails (Unconfined exception, profile drift) → Seccomp still blocks high-risk syscall classes → readOnlyRootFilesystem still prevents write exploitation → Capabilities still block privileged operationsIf both fail → Capabilities + PSS Restricted still constrain privilege → Detection (Falco/Tetragon) becomes your last active layer → NetworkPolicy still limits lateral movement
This framing changes how you think about rollout decisions. A team that disables AppArmor under incident pressure hasn’t removed one control — they’ve removed one layer of a degradation chain. The question is: which other layers are still in place, and are they configured to compensate?
It also informs how you instrument for failure. Monitoring that seccomp is applied (via the pod’s securityContext) and AppArmor is loaded (via aa-status) should be part of your cluster’s security posture signals — not one-time setup validation.
Key Takeaways
AppArmor’s value comes from how you operate it, not that you’ve enabled it. Seccomp’s value comes from the specificity of your profile, not the existence of one.
RuntimeDefault for both is not a security posture — it’s a starting point. RuntimeDefault seccomp blocks ~44 high-risk syscalls but doesn’t cover newer attack surfaces like io_uring. RuntimeDefault AppArmor is not a single well-defined thing; modern runtimes have converged but differences remain, and those differences matter in hardened environments.
AppArmor has real blind spots: network exfiltration, in-memory attacks, kernel exploits, and path-based bypass via mount manipulation. Seccomp has its own: it cannot enforce path-level access control, cannot reason about what allowed syscalls operate on, and cannot make stateful policy decisions. These aren’t reasons to skip either control — they’re reasons to understand what you’re actually enforcing and pair both with NetworkPolicy and runtime detection.
Custom Localhost AppArmor profiles managed declaratively via the Security Profiles Operator, combined with custom seccomp profiles scoped to actual workload behavior, are the only way to get a consistent, auditable posture at scale.
On modern kernels with LSM stacking, AppArmor, BPF-LSM, and Landlock can coexist — enabling layered MAC enforcement that goes beyond any single module. eBPF-based systems like Tetragon express things AppArmor and seccomp cannot: dynamic, context-aware enforcement based on process ancestry and runtime state. These are complementary layers, not alternatives.
When something goes wrong, AppArmor denial logs are among your highest-quality signals for distinguishing misconfiguration from intrusion. Build that triage path before you need it.
The Real Purpose of AppArmor
AppArmor’s goal is not to stop every exploit. No single control does that.
Its goal is to force attackers to cross more boundaries — and to create high-fidelity signals when they try.
A compromised container under a well-authored AppArmor profile cannot silently read credentials, probe /proc, write to kernel interfaces, or move laterally via the filesystem. The attacker’s options narrow, and each attempt they make is logged with enough context to tell you exactly what was tried.
In modern Kubernetes platforms, AppArmor and seccomp are most valuable not as standalone controls, but as two layers in a deliberate architecture:
| Layer | What it restricts | Enforcement point |
|---|---|---|
| Seccomp | Which syscalls the kernel will execute | Before kernel entry (cBPF filter) |
| AppArmor | What objects permitted syscalls can access | LSM hooks during kernel execution |
| NetworkPolicy | Where data can go | iptables / eBPF dataplane |
| Runtime detection | When behavior deviates from baseline | eBPF observability (Falco, Tetragon) |
No single control is sufficient. The platform architecture is the control — and these two layers together make the attack surface explicit, auditable, and enforceable at both the syscall invocation and object access levels.
One framing worth keeping: Kubernetes doesn’t implement these controls — it orchestrates them. securityContext, appArmorProfile, and seccompProfile are instructions to the Linux kernel. The real enforcement always happens below the Kubernetes abstraction layer, in the kernel’s syscall path. Understanding that boundary is what prevents “we have AppArmor configured” from being confused with “we have AppArmor enforcing what we think it is.”
Security is not about stacking controls — it’s about understanding where each control stops.
If You Remember Only One Thing Per Control
| Control | What it does | What it doesn’t do |
|---|---|---|
| Seccomp | Reduces which syscalls the kernel will execute | Cannot restrict what allowed syscalls operate on |
| AppArmor | Reduces which objects processes can access | Cannot block syscall invocation |
| Capabilities | Reduces which privileged operations are allowed | Neither path-aware nor syscall-surface aware |
| NetworkPolicy | Restricts where data can go | No visibility into process behavior |
| Runtime detection | Catches deviation from baseline behavior | Detection, not prevention |
The table is also a checklist: if you can’t articulate what each layer doesn’t cover, you’re configuring controls, not designing a security posture.
Closing Thoughts
The engineers who get this right aren’t the ones who’ve read the most documentation. They’re the ones who’ve been paged at 2am, watched a team disable AppArmor under pressure and never re-enable it, and learned the hard way that “we have security controls” and “we know what our security controls actually enforce” are different claims.
AppArmor and seccomp are not hard to enable. They’re hard to operate correctly over time — as applications change, nodes are replaced, sidecars are added, and profiles drift silently out of sync. The tooling exists to do this well: the Security Profiles Operator for lifecycle management, SPO’s record mode for profile generation, SIEM integration for denial signals, and eBPF-based detection for the gaps neither control can fill.
What separates a security posture from a compliance checkbox is whether you’ve thought through the failure modes — what happens when a profile is missing, when a runtime changes its defaults, when a team adds Unconfined during an incident. That’s the work. The YAML is the easy part.
For a deeper understanding of the syscall mechanics that both controls rely on, see the companion post: Syscalls in Kubernetes: The Invisible Layer That Runs Everything.

Leave a comment