
Written from the perspective of a senior engineer who has built, debugged, and battle-tested operators in production.
Table of Contents
- Why Operators Exist
- The Conceptual Foundation: Control Theory
- Kubernetes API Machinery: The Backbone
- Custom Resource Definitions (CRDs)
- The Controller Runtime: Inside the Engine
- Informers, Listers, and the Cache
- The Reconciliation Loop in Depth
- Work Queues and Rate Limiting
- Watches, Events, and Predicates
- Ownership, Finalizers, and Garbage Collection
- Status Subresource and Conditions
- Generation vs ObservedGeneration: A Deep Dive
- Concurrency, MaxConcurrentReconciles, and Cache Scoping
- Leader Election
- Webhooks: Admission and Conversion
- Operator Patterns and Anti-Patterns
- Observability and Debugging
- Production Considerations
- Ready to Build Your Own Operator
Why Operators Exist
Before we dive into internals, let’s get philosophical for a moment. Kubernetes gives you primitives: Pods, Deployments, Services, ConfigMaps. These are general-purpose building blocks. They’re powerful, but they’re dumb — they don’t understand your application’s operational semantics.
Consider a PostgreSQL cluster. A skilled DBA knows:
- How to perform a rolling upgrade without downtime
- When and how to promote a standby to primary during a failure
- How to orchestrate backups in a consistent way
- How to resize volumes without data loss
None of this knowledge lives in native Kubernetes. An Operator is the mechanism to codify operational expertise into software that runs inside your cluster and manages resources on your behalf.
The formal definition: An Operator is a custom controller that manages Custom Resources to automate complex, stateful application lifecycle management.
The Conceptual Foundation: Control Theory
Every operator is, at its core, an implementation of a closed-loop control system — specifically what control engineers call a feedback control loop.

The three core concepts are:
Desired State — What you declare in your Custom Resource (the spec field). This is immutable intent.
Observed State — What’s actually running in the cluster right now (the status field plus the state of managed child resources).
Reconciliation — The act of computing the delta between desired and observed state, then taking actions to close that gap.
Controllers are implemented on top of event streams (watch events from the Kubernetes API), but their reconciliation logic is level-based, not edge-triggered. The trigger is event-driven; the behavior is not. Rather than reacting once to a specific event, the controller always asks “is the world in the state I want?” and drives toward that state regardless of how many events fired. This distinction matters enormously for resilience: if you miss an event, the next reconciliation catches it anyway. Contrast this with a purely edge-triggered system where a missed event means a missed action — permanently.
Kubernetes API Machinery: The Backbone
Before building or understanding operators, you need a solid mental model of how the Kubernetes API server works.
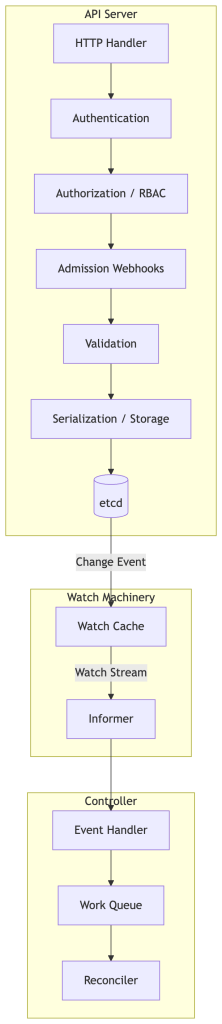
Every object in Kubernetes is stored in etcd as a versioned, typed resource. The API server exposes these objects via a RESTful interface. Critically, the API server supports a Watch mechanism — clients can subscribe to a stream of events for any resource type.
The watch stream delivers three event types: ADDED, MODIFIED, DELETED. These are the raw signals your controller eventually acts on, though — as we’ll see — the controller runtime abstracts this considerably.
Resource Versions are central to the concurrency model. Every object has a resourceVersion field — an opaque string used for optimistic concurrency control. It is derived from etcd’s internal revision mechanism, but clients must always treat it as opaque: never parse it, compare it numerically, or make assumptions about its format. When you update an object, you must send the current resourceVersion to guarantee a compare-and-swap, preventing lost updates in concurrent environments.
Custom Resource Definitions
CRDs are how you extend the Kubernetes API. When you apply a CRD, the API server dynamically registers new API endpoints, enables storage in etcd, and starts serving your custom resources as first-class API objects.
A CRD has several important structural components:
apiVersion: apiextensions.k8s.io/v1kind: CustomResourceDefinitionmetadata: name: databases.mycompany.iospec: group: mycompany.io names: kind: Database plural: databases singular: database shortNames: ["db"] scope: Namespaced versions: - name: v1alpha1 served: true storage: true schema: openAPIV3Schema: # Structural schema for validation subresources: status: {} # Enables /status subresource scale: # Optional: enables /scale subresource specReplicasPath: .spec.replicas statusReplicasPath: .status.replicas additionalPrinterColumns: - name: Phase type: string jsonPath: .status.phase
The status subresource deserves special attention. When enabled, spec and status become separately updatable — meaning only the controller should write to status, and users should only write to spec. This enforces a clean separation of intent vs. observation.
Structural Schema is mandatory since apiextensions.k8s.io/v1 (Kubernetes 1.16+). Non-structural schemas are rejected by the API server. The openAPIV3Schema field defines the shape of your resource and enables server-side validation — every field must be described. This prevents garbage data from entering your system.
The Controller Runtime: Inside the Engine
The controller-runtime library (used by both Kubebuilder and Operator SDK) provides the scaffolding that most operators are built on. Let’s dissect what it gives you.
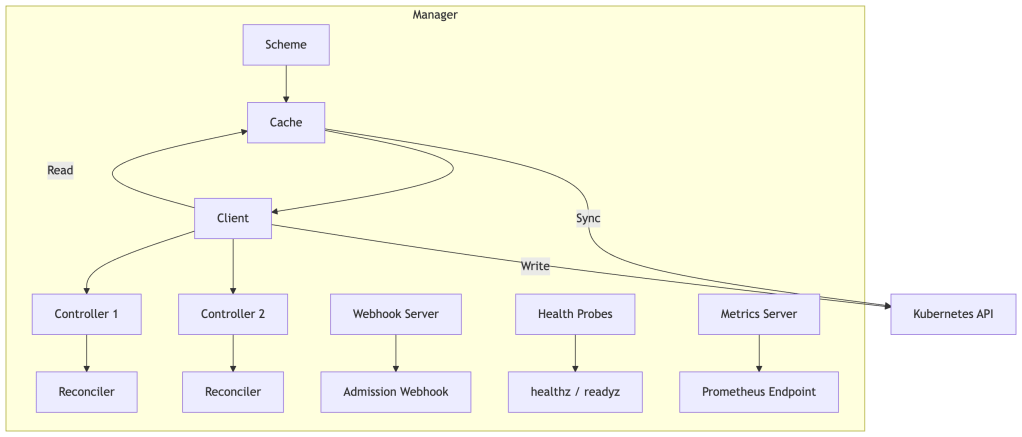
The Manager is the top-level orchestrator. It:
- Manages a shared cache (backed by informers) for all resource types your controllers care about
- Provides a client that reads from the local cache and writes directly to the API server
- Runs all controllers in goroutines
- Handles leader election
- Exposes health check and metrics endpoints
The Cache is the performance secret. Rather than every reconciliation hitting the API server, reads go to a local in-memory store that is kept in sync via informers. This reduces API server load dramatically and makes your operator fast.
The Client has two personalities:
- Reader (cache-backed): Fast, eventually consistent. Used for
GetandListoperations during reconciliation. If you need strong consistency at a specific checkpoint, you can bypass the cache by constructing an uncached client — but do so sparingly, as it adds latency and API server load. - Writer (direct to API): Used for
Create,Update,Patch,Delete, andStatus().Update(). These always go directly to the API server, never through the cache.
Informers, Listers, and the Cache
This is where things get really interesting from an internals perspective. The Informer is the heart of the watch machinery.
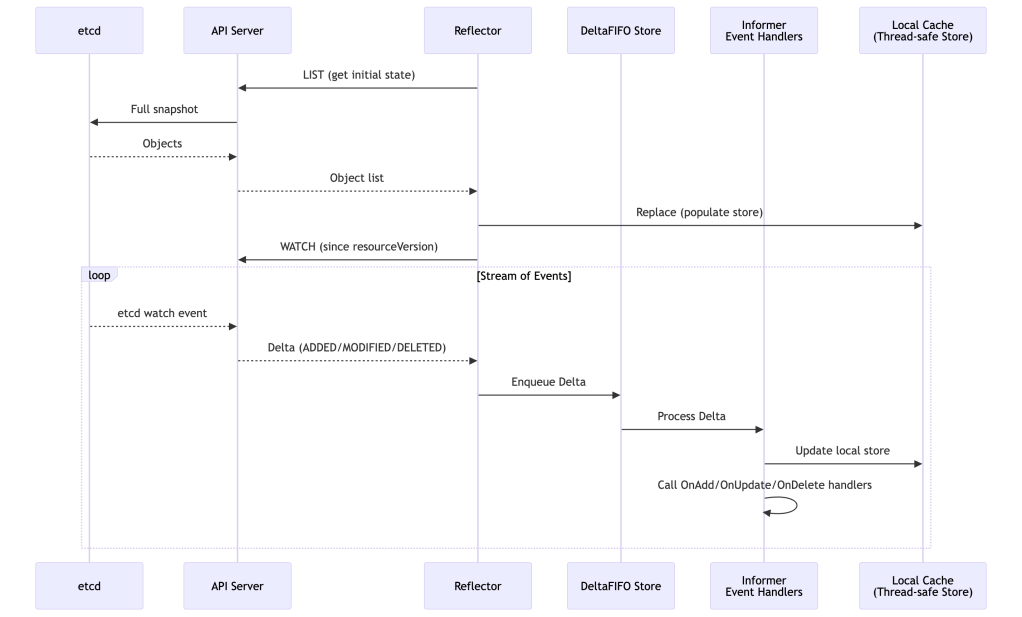
The Reflector does the heavy lifting: it first performs a List to establish the initial state, then starts a long-lived Watch. If the watch connection drops (network blip, API server restart), the reflector automatically reconnects and re-lists if necessary.
The DeltaFIFO queue is a clever data structure that deduplicates events for the same object. If an object is modified 10 times before the controller gets around to processing it, they’re collapsed. This is the first layer of the “level-triggered” behavior.
The Local Cache (a thread-safe store with indexes) is what client.Get and client.List read from. It’s always slightly behind the API server (eventual consistency), but that’s acceptable because your reconciler should be idempotent anyway.
Listers are typed wrappers over the cache that let you query by namespace or label selector without hitting the network.
The Reconciliation Loop in Depth
Here’s the full picture of what happens from a watch event to a completed reconciliation:
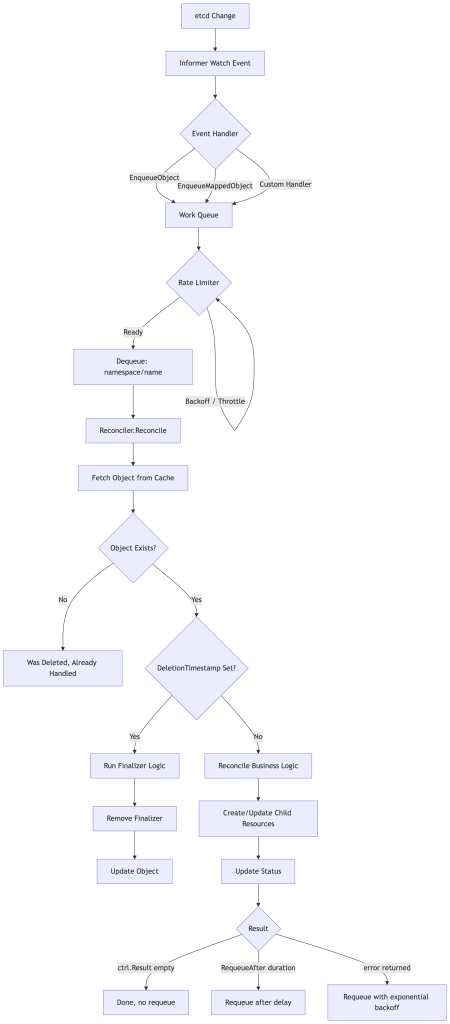
A few nuances that trip people up:
The key is a namespace/name pair, not an object. When your reconciler is called, you only get the namespace and name. You must re-fetch the current state of the object from the cache. Never trust stale data passed in — always re-read at the top of your reconcile function.
Reconcile should be idempotent. It will be called multiple times for the same state. If you create a resource, check if it already exists first. If you apply a configuration, make it declarative. A reconcile that is accidentally destructive when called twice is a ticking time bomb.
Errors vs. Requeue. Returning an error causes the item to be requeued with exponential backoff (respecting the rate limiter). Returning ctrl.Result{Requeue: true} or ctrl.Result{RequeueAfter: duration} requeues without registering an error (no backoff increment). Use the former for actual errors, the latter for polling scenarios.
Work Queues and Rate Limiting
The work queue deserves its own section because it’s where many operator performance issues originate.
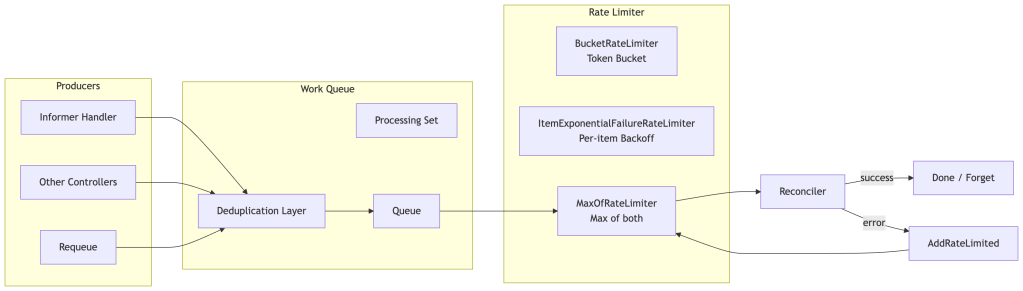
The work queue has a built-in deduplication guarantee: if the same namespace/name is already in the queue, adding it again is a no-op. This means a burst of 100 events for the same object results in exactly one reconciliation.
The Processing Set ensures that while an item is being reconciled, any new events for that same item are queued but not dispatched until the current reconciliation completes. This prevents concurrent reconciliations for the same object.
Rate limiters in controller-runtime compose two strategies:
The ItemExponentialFailureRateLimiter tracks per-item failure counts and applies backoff: base * 2^failures up to a maximum. This prevents a persistently failing object from hammering the API server.
The BucketRateLimiter is a global token bucket that caps overall reconciliation throughput. This protects the API server from a thundering herd when many objects need reconciliation simultaneously (e.g., after an operator restart).
The default controller-runtime rate limiter combines per-item exponential backoff (base ~5ms, max ~1000s) with a global token bucket (~10 QPS, burst ~100). These defaults can vary across controller-runtime versions and are not guaranteed API contracts — always verify against your version’s source. In high-scale environments, you’ll almost certainly want to tune them.
Watches, Events, and Predicates
A controller needs to know which objects to watch. The .Watches() builder in controller-runtime lets you express complex watch topologies.
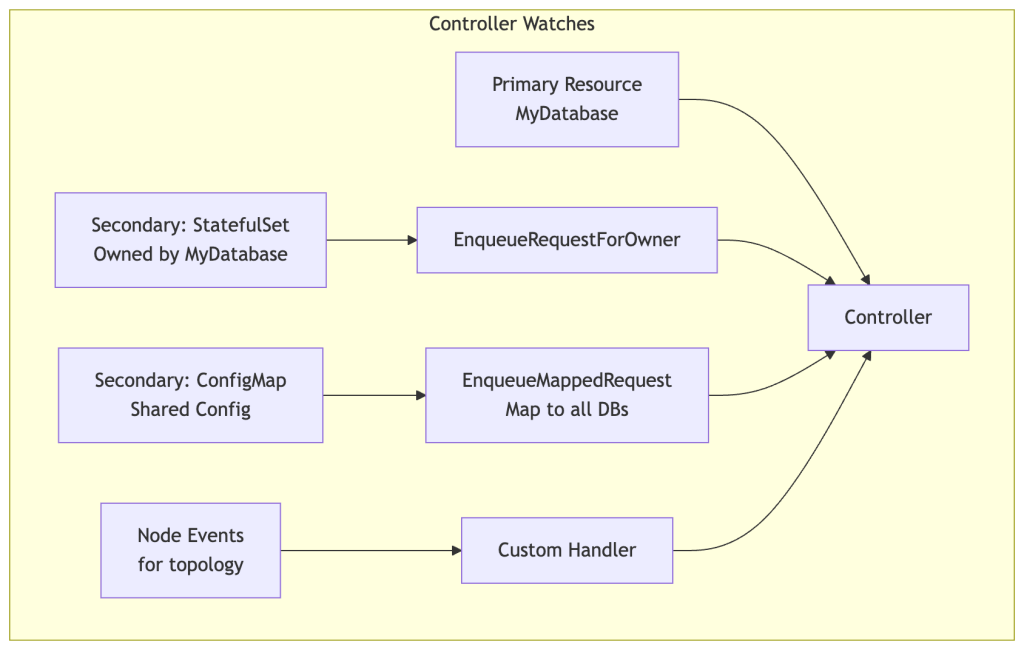
EnqueueRequestForOwner is the most common pattern: when a child resource changes (e.g., a Pod owned by your operator’s StatefulSet), find the owner reference chain and enqueue the root owner. This lets the parent controller react to child state changes.
EnqueueMappedRequest (formerly EnqueueRequestsFromMapFunc) is a powerful escape hatch. Given any object event, you provide a function that maps it to zero or more reconcile requests. Use this for non-ownership relationships — e.g., when a shared Secret changes, requeue all operators that reference it.
Predicates filter events before they hit the queue. This is a critical optimization that’s often overlooked:
// Only reconcile when spec changes, not on every status updatectrl.NewControllerManagedBy(mgr). For(&myv1.Database{}, builder.WithPredicates(predicate.GenerationChangedPredicate{})). Complete(r)
GenerationChangedPredicate is particularly valuable — it only triggers reconciliation when metadata.generation increments (which only happens on spec changes), ignoring pure status updates. Without this, every status write your controller does triggers another reconciliation, creating a tight loop.
Ownership, Finalizers, and Garbage Collection
This triad is where operator bugs tend to cluster. Let’s be precise.
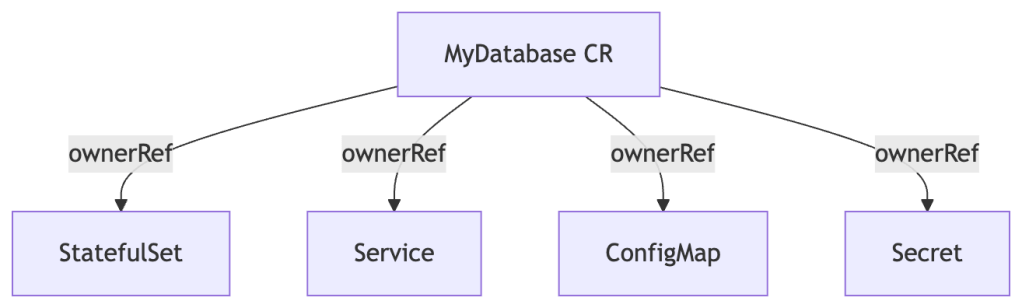
Owner References establish the parent-child relationship for garbage collection:
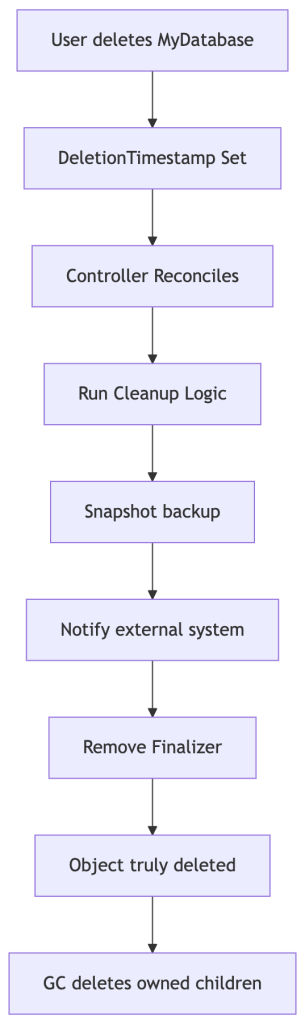
Finalizer deletion flow — what happens step by step when a user deletes an object with a finalizer:
Owner references tell the Kubernetes garbage collector that child objects should be deleted when the parent is deleted. Always set owner references on resources you create — without them, orphaned resources accumulate in the cluster.
ctrl.SetControllerReference(database, statefulSet, r.Scheme)
This sets the child’s metadata.ownerReferences to point to the parent, with controller: true and blockOwnerDeletion: true.
Finalizers are strings in metadata.finalizers that prevent an object from being deleted until all finalizers are removed. When a user deletes an object with finalizers, Kubernetes sets metadata.deletionTimestamp but doesn’t remove the object. Your controller must detect this, do cleanup work, remove its finalizer, and then update the object — at which point Kubernetes deletes it.
Common finalizer pattern:
const myFinalizer = "mycompany.io/database-finalizer"func (r *Reconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) { db := &myv1.Database{} if err := r.Get(ctx, req.NamespacedName, db); err != nil { return ctrl.Result{}, client.IgnoreNotFound(err) } if !db.DeletionTimestamp.IsZero() { // Object is being deleted if controllerutil.ContainsFinalizer(db, myFinalizer) { if err := r.runCleanup(ctx, db); err != nil { return ctrl.Result{}, err } controllerutil.RemoveFinalizer(db, myFinalizer) return ctrl.Result{}, r.Update(ctx, db) } return ctrl.Result{}, nil } // Add finalizer if not present if !controllerutil.ContainsFinalizer(db, myFinalizer) { controllerutil.AddFinalizer(db, myFinalizer) return ctrl.Result{}, r.Update(ctx, db) } // Normal reconciliation...}
A critical warning: Finalizer logic must be robust and eventually complete. A finalizer that never removes itself will prevent the object from being garbage collected forever. Always provide a way to force-remove the finalizer in operational runbooks.
Status Subresource and Conditions
Your operator’s primary communication channel with users (and other systems) is the status field. Get this right.
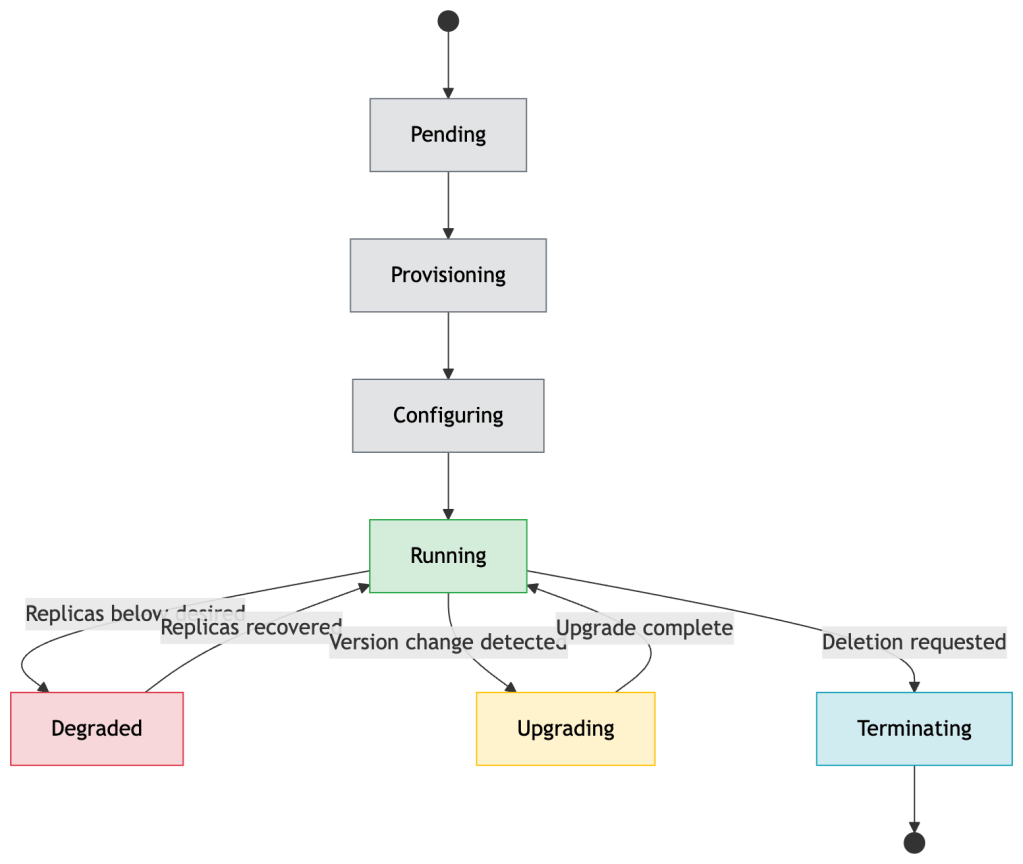
Always use the Conditions pattern for status. It’s the Kubernetes-idiomatic way to communicate multi-dimensional state. The example below uses condition types modeled after the common Kubernetes Deployment pattern — adapt the types to your domain:
status: phase: Running observedGeneration: 5 # which spec generation this status reflects conditions: - type: Ready status: "True" lastTransitionTime: "2024-01-15T10:00:00Z" reason: AllReplicasReady message: "3/3 replicas are ready" - type: Progressing status: "False" lastTransitionTime: "2024-01-15T10:01:00Z" reason: ReplicaSetAvailable message: "Rollout complete" - type: Available status: "True" lastTransitionTime: "2024-01-14T08:00:00Z" reason: MinimumReplicasAvailable message: "Deployment has minimum availability"
observedGeneration is critical and frequently missed. It tells observers which version of the spec this status corresponds to. Without it, you can’t tell if status.phase: Running means “running the spec you just applied” or “running an older spec while the new one is being processed.”
Always update status with r.Status().Update(ctx, obj) not r.Update(ctx, obj). The status subresource has a separate endpoint and a separate RBAC policy. The main update endpoint ignores status changes; the status endpoint ignores spec changes.
Generation vs ObservedGeneration: A Deep Dive
This is one of the most misunderstood mechanics in operator development, yet it’s fundamental to building correct status reporting. Let’s be precise.
metadata.generation is a monotonically incrementing integer managed entirely by the API server. It increments only when the spec changes — status updates, label changes, and annotation changes do not increment it. This is why GenerationChangedPredicate works: it filters out the noise.
status.observedGeneration is a field your controller writes to status after completing a reconciliation. It should be set to the metadata.generation value of the object you just reconciled.
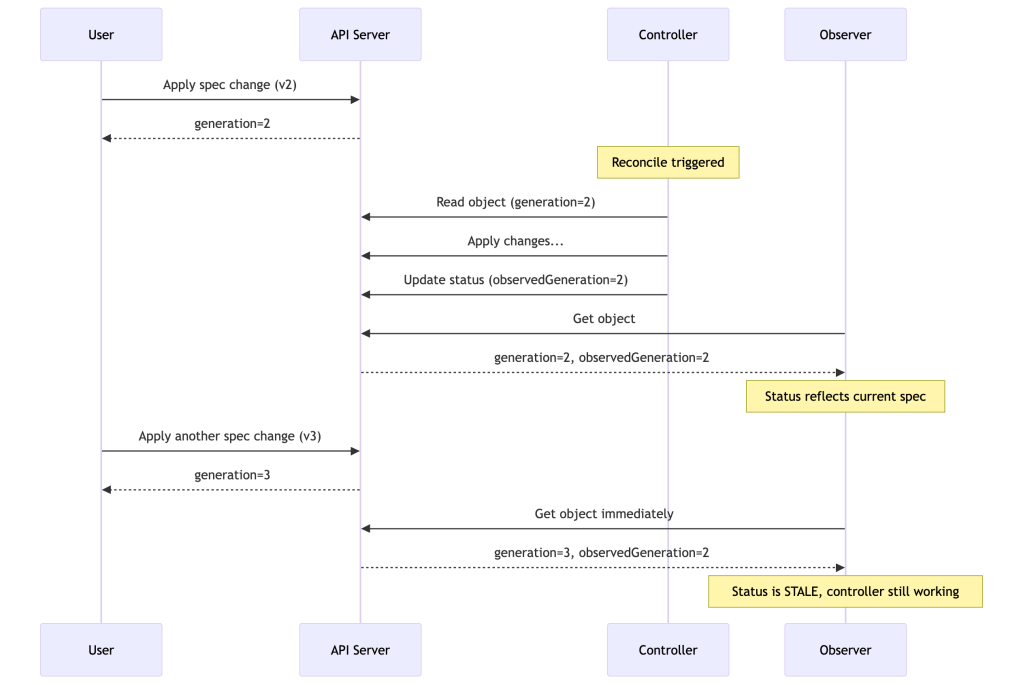
The pattern lets any observer — including kubectl wait, GitOps controllers, and your own tooling — determine whether the controller has finished processing the latest spec without any out-of-band signaling:
func (r *Reconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) { db := &myv1.Database{} if err := r.Get(ctx, req.NamespacedName, db); err != nil { return ctrl.Result{}, client.IgnoreNotFound(err) } // ... reconcile logic ... // At the end: stamp observedGeneration db.Status.ObservedGeneration = db.Generation db.Status.Phase = "Running" return ctrl.Result{}, r.Status().Update(ctx, db)}
Without observedGeneration, a status.phase: Running is ambiguous — it could mean “running the spec you just applied 30 seconds ago” or “running an old spec that’s three versions behind.” With it, observers have a precise, reliable signal.
Concurrency, MaxConcurrentReconciles, and Cache Scoping
MaxConcurrentReconciles
By default, controller-runtime runs one reconciler goroutine per controller. For many operators this is fine, but for operators managing hundreds or thousands of independent custom resources, this is a significant throughput bottleneck. Enter MaxConcurrentReconciles:
ctrl.NewControllerManagedBy(mgr). For(&myv1.Database{}). WithOptions(controller.Options{ MaxConcurrentReconciles: 10, }). Complete(r)
This allows up to 10 reconciler goroutines to run in parallel for different objects. A few important points:
The work queue guarantees per-object serialization. Even with MaxConcurrentReconciles: 10, the same namespace/name key will never be dispatched to two goroutines simultaneously. You get concurrency across different objects, not within a single object’s reconciliation chain.
Your reconciler must be goroutine-safe. Any shared state (metrics counters, caches, client connections) must be safe for concurrent access. The controller-runtime client is safe. Custom state you add to the reconciler struct is your responsibility.
Rate limiting still applies globally. High MaxConcurrentReconciles combined with a tight rate limiter creates goroutines waiting on the rate limiter. Tune both together.
A good starting heuristic: set MaxConcurrentReconciles to roughly the number of objects you expect divided by the average reconcile latency in seconds. For 1000 objects reconciling in ~500ms each, MaxConcurrentReconciles: 5 gives you comfortable throughput headroom.
Cache Scoping for Large Clusters
By default, the controller-runtime cache watches all namespaces. In large multi-tenant clusters this can mean caching thousands of objects your operator doesn’t care about. Cache scoping is the solution:
mgr, err := ctrl.NewManager(cfg, ctrl.Options{ Cache: cache.Options{ // Only cache objects in specific namespaces DefaultNamespaces: map[string]cache.Config{ "tenant-a": {}, "tenant-b": {}, }, },})
Field indexing is another powerful tool. If your reconciler frequently lists objects filtered by a custom field, add an index to the cache:
// Index Databases by their referenced Secret nameif err := mgr.GetFieldIndexer().IndexField( ctx, &myv1.Database{}, ".spec.credentialsSecret", func(obj client.Object) []string { db := obj.(*myv1.Database) return []string{db.Spec.CredentialsSecret} },); err != nil { return err}// Now you can efficiently list all DBs referencing a secretdbList := &myv1.DatabaseList{}r.List(ctx, dbList, client.MatchingFields{".spec.credentialsSecret": secretName})
Without an index, this List does a full cache scan. With it, it’s an O(1) lookup. At scale, this is the difference between a 1ms and 200ms reconciliation.
Optimistic Locking and Conflict Retries
API server conflicts (409 Conflict) are a normal part of operating at scale. When your reconciler reads an object, modifies it, and writes it back — and something else has modified it in between — you get a conflict. The correct response is to re-read and retry:
import "k8s.io/client-go/util/retry"err := retry.RetryOnConflict(retry.DefaultRetry, func() error { // Re-fetch to get the latest resourceVersion if err := r.Get(ctx, req.NamespacedName, db); err != nil { return err } // Apply your changes to the freshly-fetched object db.Status.Phase = computedPhase return r.Status().Update(ctx, db)})
retry.DefaultRetry uses exponential backoff (5 retries, 10ms base, 1.0 jitter). For status updates this is usually sufficient. For spec updates, prefer server-side apply which handles conflicts at the field ownership level rather than requiring a full re-read/retry.
Leader Election
In production, you run multiple replicas of your operator for high availability. But you don’t want multiple replicas simultaneously reconciling the same objects — that leads to conflicts and thrashing. Leader election solves this.
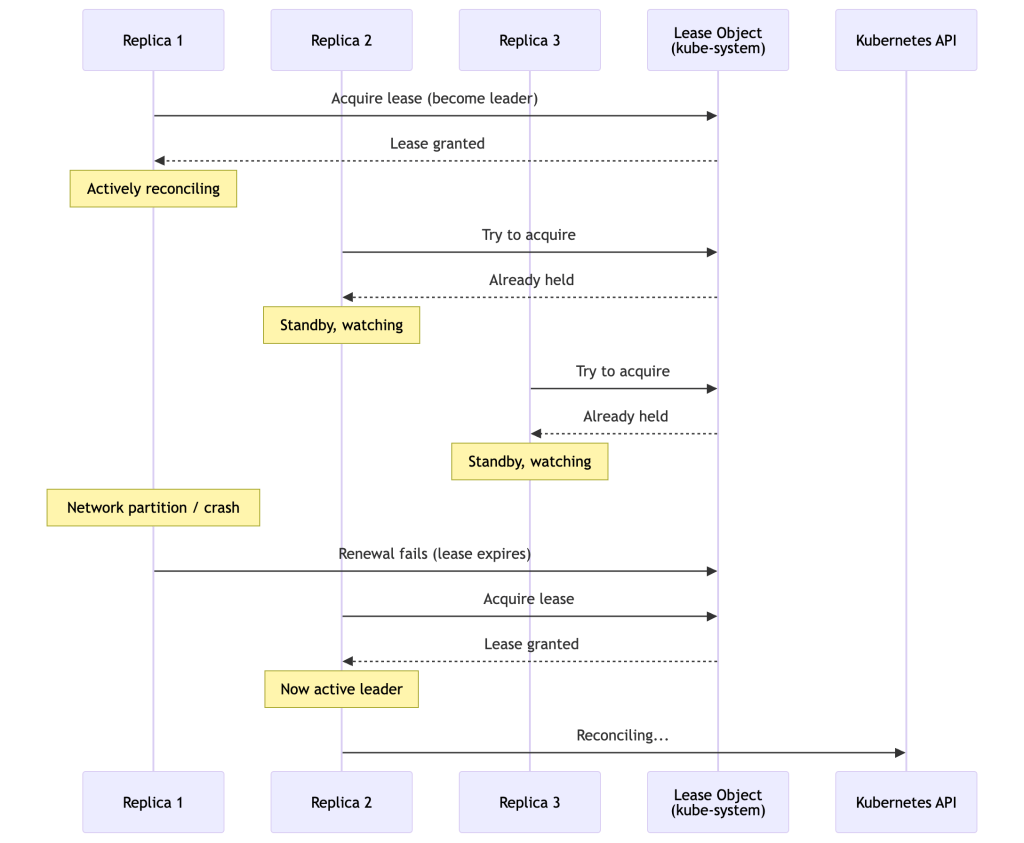
Controller-runtime uses a Lease object in the cluster as the distributed lock. The leader holds the lease by periodically renewing it. If the leader fails to renew before the lease expires, another replica acquires it.
Configuration in controller-runtime:
mgr, err := ctrl.NewManager(cfg, ctrl.Options{ LeaderElection: true, LeaderElectionID: "my-operator-leader", LeaderElectionNamespace: "my-operator-system", LeaseDuration: &leaseDuration, // default 15s RenewDeadline: &renewDeadline, // default 10s RetryPeriod: &retryPeriod, // default 2s})
Standby replicas still run the cache — they maintain informers and local caches, but they don’t start the controllers. This means failover is fast (no cold start for the informer sync) because the new leader already has a warm cache.
Important nuance: Leader election reduces the likelihood of concurrent reconciliations, but it does not eliminate it entirely. During the lease expiry window, a brief overlap is possible where both the old and new leader are active. Controllers must still be written to tolerate conflicts and retries. Never assume strict single-threaded execution at the cluster level — your reconciler must be safe to run concurrently.
Caution: Leader election adds latency to recovery. With LeaseDuration=15s, a leader failure can cause up to 15 seconds of no-reconciliation. Tune this based on your operator’s latency requirements.
Webhooks: Admission and Conversion
Webhooks are the mechanism to inject logic into the API server’s request pipeline.
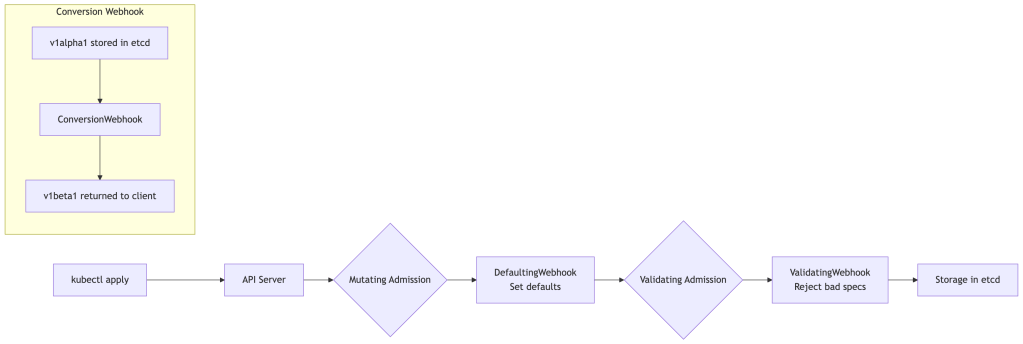
Defaulting Webhooks (MutatingAdmissionWebhook) run before storage and let you inject default field values. This is essential for forward compatibility — when you add a new required field to v2 of your CRD, a defaulting webhook can populate it for resources created without it.
Validating Webhooks (ValidatingAdmissionWebhook) run after mutation and let you reject invalid requests with human-readable error messages. This is where you enforce complex business rules that can’t be expressed in OpenAPI schema (cross-field validation, external system checks, etc.).
Conversion Webhooks are needed when you have multiple active API versions of a CRD. The API server stores objects in one version (the storage: true version) but can serve them in other versions. Conversion webhooks handle the transformation between versions.
// controller-runtime webhook setupfunc (r *Database) Default() { if r.Spec.Replicas == nil { defaultReplicas := int32(1) r.Spec.Replicas = &defaultReplicas }}func (r *Database) ValidateCreate() (admission.Warnings, error) { if r.Spec.StorageSize.Cmp(minStorage) < 0 { return nil, fmt.Errorf("storage size must be at least %s", minStorage.String()) } return nil, nil}
Webhooks require TLS certificates and must be running before the API server can call them. Certificate management is operationally annoying — use cert-manager or controller-runtime’s built-in certificate provisioner.
Operator Patterns and Anti-Patterns
After years of writing and reviewing operators, here’s the distilled wisdom:
Patterns to Follow
Adopt Whenever Possible: Use server-side apply (client.Apply) instead of create-or-update. It’s declarative, handles field ownership correctly, and is idempotent by design. One critical caveat: if you adopt SSA, use it consistently for all managed resources. Mixing Update and Apply on the same fields causes managedFields ownership conflicts that are painful to debug and resolve.
// Instead of create-or-update dance:patch := client.Applyobj.ManagedFields = nil // Let SSA manage thiserr = r.Patch(ctx, obj, patch, client.ForceOwnership, client.FieldOwner("my-operator"))
Use Patch over Update: Always prefer Patch (specifically strategic merge patch or JSON patch) over Update for status and spec changes. Update replaces the entire object and is prone to conflicts; Patch is surgical and conflict-resistant.
Emit Events: Use the Event recorder to emit Kubernetes events for significant state transitions. This gives users visibility via kubectl describe:
r.Recorder.Event(db, corev1.EventTypeWarning, "ProvisioningFailed", "Failed to create PVC")
Separate controllers for separate concerns: Don’t build a monolithic reconciler. If your operator manages both the database cluster and its backup schedule, use two controllers with a shared cache.
Anti-Patterns to Avoid
Don’t store state in the controller process. Your controller can be restarted, scaled, or fail over at any moment. The only source of truth is the Kubernetes API. If you need to persist computed state, put it in status or in a ConfigMap.
Don’t busy-loop with short requeue intervals. In most cases, sub-10-second polling intervals are unnecessary and wasteful. Prefer watch-based triggers unless the external system cannot emit events. For fast-moving, short-lived state machines (e.g., managing transient Jobs), shorter intervals may be valid — but they should be the exception, not the default. If you truly need polling, make the interval configurable so it can be tuned per deployment.
Don’t ignore resourceVersion conflicts. A 409 Conflict from the API server means someone else updated the object between your read and write. The correct response is to re-fetch and retry, not to log and continue.
Don’t call the API server inside tight loops. Fetching all pods to check readiness in a loop that runs every reconciliation is expensive. Use the cache, or precompute what you need at the start of reconciliation.
Don’t use Update when Patch will do. Using r.Update(ctx, obj) after modifying the spec will overwrite any changes made between your read and your write. Prefer patch operations.
Observability and Debugging
An operator you can’t observe is an operator you can’t trust in production.
Metrics
Controller-runtime exports Prometheus metrics out of the box:
# Work queue depth — a leading indicator of reconciliation backlogworkqueue_depth{name="database"} 42# Reconcile duration histogram — p99 tells you about slow reconciliationscontroller_runtime_reconcile_time_seconds_bucket{controller="database", le="0.1"} 1000# Reconcile errors — should be near zero in steady statecontroller_runtime_reconcile_errors_total{controller="database"} 5# Active goroutines in the work queueworkqueue_work_duration_seconds_bucket{name="database"}
Always add custom metrics for your domain:
var databasesProvisioning = prometheus.NewGauge(prometheus.GaugeOpts{ Name: "myoperator_databases_provisioning", Help: "Number of databases currently in provisioning state",})
Structured Logging
Use structured logging (logr interface) with consistent fields:
log := log.FromContext(ctx).WithValues( "database", req.NamespacedName, "generation", db.Generation, "phase", db.Status.Phase,)log.Info("Starting reconciliation")
Tracing
For complex operators with many API calls, distributed tracing (OpenTelemetry) provides invaluable insight into where time is spent during reconciliation.
Common Debugging Commands
# Watch reconciler output in real timekubectl logs -n operator-system deploy/my-operator -f | jq '.'# Inspect the CRD resource including statuskubectl get database mydb -o yaml# Check events for a custom resourcekubectl describe database mydb# Force a reconcile by touching the annotationkubectl annotate database mydb force-reconcile=$(date +%s) --overwrite# Check lease for leader electionkubectl get lease -n operator-system
Production Considerations
Resource Management
Always set resource requests and limits on your operator pod. An operator without limits can starve other workloads during a reconciliation storm.
RBAC Least Privilege
Your operator’s ServiceAccount should only have the permissions it actually needs. A common mistake is granting cluster-admin for convenience. Use the Kubebuilder RBAC markers to generate precise RBAC manifests:
//+kubebuilder:rbac:groups=mycompany.io,resources=databases,verbs=get;list;watch;create;update;patch;delete//+kubebuilder:rbac:groups=mycompany.io,resources=databases/status,verbs=get;update;patch//+kubebuilder:rbac:groups=apps,resources=statefulsets,verbs=get;list;watch;create;update;patch;delete
Graceful Shutdown
Handle SIGTERM gracefully. The controller-runtime manager’s Start function blocks until context cancellation, at which point it stops all controllers and waits for in-flight reconciliations to complete (up to a timeout). Make sure your reconciler respects context cancellation:
func (r *Reconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) { // Check context at expensive checkpoints select { case <-ctx.Done(): return ctrl.Result{}, ctx.Err() default: } // ... reconcile logic}
Testing Strategy
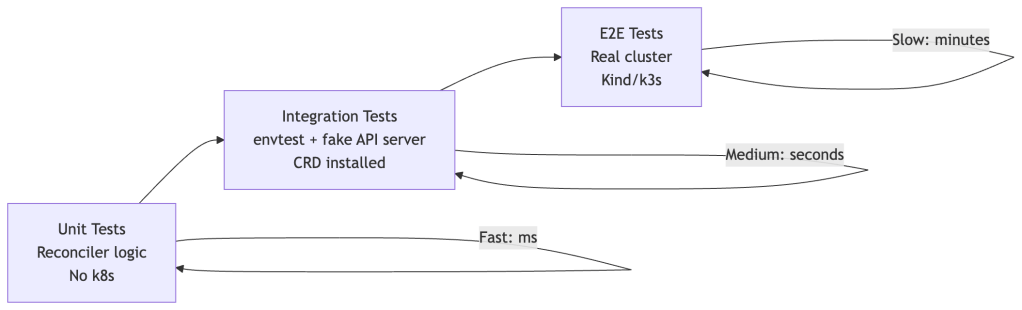
Use envtest (from controller-runtime) for integration tests. It spins up a real etcd and API server, installs your CRDs, and lets you test full reconciliation loops without a cluster. This is your most valuable testing layer.
Upgrade Considerations
When upgrading your operator, consider:
- CRD schema changes: Adding fields is safe. Removing or renaming fields is breaking. Use conversion webhooks for major schema evolution.
- Controller logic changes: New reconciler behavior applied to existing resources — think through the transition. Add a migration annotation or one-time migration job if needed.
- State machine transitions: If you’re adding new phases to your state machine, ensure existing resources in “old” phases are handled by the updated controller.
Conclusion
Kubernetes Operators are one of the most powerful extension mechanisms ever built into a distributed system platform. But that power comes with complexity. The controller runtime, informers, work queues, rate limiters, finalizers, and webhooks form a sophisticated machinery that, once understood, enables you to build remarkably robust automation.
The key mental models to internalize:
Level-triggered reconciliation — always reconcile toward desired state, don’t just react to events. This gives you resilience for free.
The cache is your friend — reads from cache, writes to API. This is the performance contract the entire system is designed around.
Idempotency is not optional — your reconciler will be called many times for the same state. Design it accordingly from day one.
Status is a contract — observedGeneration, conditions with reasons and messages, precise phase transitions. This is how your operator communicates with the world.
The operators you build are, in a very real sense, pieces of software that will run 24/7, autonomously managing production infrastructure. Treat them with the same rigor you’d apply to any production-critical system: test thoroughly, observe everything, and design for failure.
Ready to Build Your Own Operator?
If you want to go from zero to production-ready Kubernetes operators with hands-on practice, check out the Kubernetes Operators Course — a practical, end-to-end course that walks you through building operators from the basics all the way to production-grade patterns. It’s a great companion to the internals covered in this post.
Found a bug or inaccuracy? The beauty of operators — and this blog post — is that there’s always room for a reconciliation loop.

Leave a comment